
Scandinavian Languages Project¶
This project analyzes the different ways languages can evolve given a certain demographic context. More specifically, it analyzes the differences between the Swedish spoken in Sweden and the Swedish spoken by the ethnic minority group in Finland, also called Finnosvenka. There has been a Swedish-speaking minority in Finland since roughly the 16th century and as an isolated community, the language has hypothetically changed less than the “mainland” version of Swedish spoken in Sweden.
To test this hypothesis that Finnosvenka would have experienced less change over time than mainstream Swedish, we compare newspaper publishings from Sweden and Finland from the 18th and 19th centuries. While newspapers might not be the largest drivers of change, they demonstrate greater linguistic stability than less formal data sources. The SpråkbankenText service hosted by the University of Gothenburg has an extensive collection of newspapers from both Sweden and Finland, which we use for this analysis.
The analysis is divided into two sections. First, we take a high-level look at the trends across decades for both Swedish and Finnosvenka newspapers. This looks at the overall patterns of word usage for each linguistic groups to see if they really have evolved in different ways. The second part takes a more granular approach by looking at specific words and see how they are used over time in both the Swedish and Finnish text. By examining specific words, we can begin to hunt down potential cultural influences in the difference between Swedish and Finnosvenka over time.
import json
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
from scipy import spatial
from collections import Counter
import os
import pickle
from math import log
import numpy as np
from utils import LanguageCounter
from sklearn.decomposition import PCA
from scipy import stats
finYears = list(fin.allCounters.keys())
sweYears = list(swe.allCounters.keys())
1. The Dataset¶
The Swedish dataset comes from the Khubist-2 corpus hosted on SpråkbankenText. The newspapers span from 1750 to 1890 and come from various regions in southern Sweden, where the majority of the population is located. Due to size contraints and the much larger sample size of newspapers in Sweden, we take only a sampling of the available newspapers.
The Finnish dataset comes from Nationalbibliotekets svenskspråkiga tidningar corpus. This is a comprehensive dataset of newspapers from Finnosvenka newspapers in Finland from 1770 to 1900.
We represent each corpus as an object of the LanguageCounter object, which is defined in utils.py. Each object stores the words and their frequencies across decades. This representation saves only the word counts across decades and across languages. Later analysis could look at the grammatical structure of the texts, but for now we look at the different trends in word usage across languages.
print(LanguageCounter.__doc__)
Class used to represent each corpus.
...
Attributes
----------
dataPath: str
Path to the directory that contains the pickled raw text for each newspaper.
allCounters: Dict[np.datetime64, Counter]
A mapping from decade to a counter of each word in the newspaper publishings for that decade.
commonWords: Dict[np.datetime64, list[str]]
A mapping from decade to the top 100 most commonly used words used in that decade.
topWordsTotal: Counter
The top 250 words used across all time by the newspapers and their overall frequncies.
allFeatized: List[List[float]]
A list of 250-dimensional vectors, one for each decade of the corpus. Vectors show the frequencies of each of the topWordsTotal within that decade.
Methods
-------
buildCommonCounters(dataPath)
For every pickle file in dataPath, adds a counter for the given decade to self.allCounters
getOverlaps()
Get the amount of word overlap across decades.
buildFeatures()
Builds feature vectors that describe each decade by the frequency of each of the overall top 250 most commonly used words by the language.
finCountSource = "data/Finnish/temp_txt"
sweCountSource = "data/Swedish/"
fin = LanguageCounter(finCountSource)
fin.buildCommonCounters(fin.dataPath)
swe = LanguageCounter(sweCountSource)
swe.buildCommonCounters(swe.dataPath)
2. Overall Trends¶
First we can take a look at the overall trends across decades for each language. This well help us get a better understanding for each language and confirm that there actually are differences in how Finnosvenka and Swedish have evolved.
2.1 Measuring Word Overlaps¶
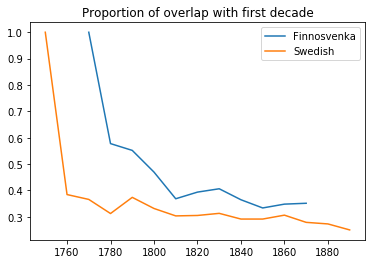
The first graph shows the proprotion of words across decades that are shared with the first decade of publishing. The Swedish data starts at 1740 and the Finnish data at 1760 with 100% overlap, since we’re comparing each decade with themselves. As soon as the next decade of publishing, both languages start to deviate from their first decade of publishing. Swedish text changes more rapidly, quickly setting at about 30% of words overlapping with the original newspaper content. Finnosvenka text takes longer to diverge from the original text and settles on a higher overlap with the original newspaper content with about 40% overlap. For a first experiment, this is a good indication that Swedish text evolves faster and more rapidly than its Finnosvenka counterpart.
# Similarity wrt 1770 decade over time
_, finSimToBase = fin.getOverlaps()
plt.plot(finYears, finSimToBase, label="Finnosvenka")
_, sweSimToBase = swe.getOverlaps()
plt.plot(sweYears, sweSimToBase, label="Swedish")
plt.legend()
plt.title("Proportion of overlap with first decade")
plt.show()
2.2 Building Decade Feature Vectors¶
This section takes a more detailed look at the similarity across decades of each langauge. We follow the same process as Two Pis in a Pod where we rerpresent decades through the use of high frequency words. The buildFeatures method will find the top 250 words across all years for each language. Each decade will then be characterized by the relative frequency of each of those 250 words in that decade. Top word frequency has been used as a reliable metric of author signature in the past. First off, it provides a sort of signature because of how an author’s characteristics will determine the ratio of commonly-used wrods. Second, by avoiding content words that would vary between Finnish and Swedish publications, we can make a more direct comparison between the stylistic choices of the two linguistic groups.
fin.buildFeatures()
swe.buildFeatures()
2.2.1 Similarity Across Time for Individual Languages¶
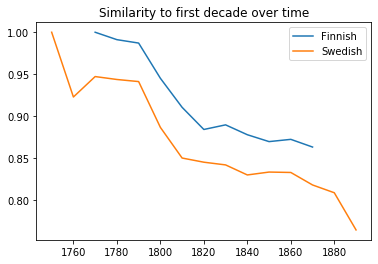
As a quick test to make sure these feature vectors make sense, we can make a similar plot to section 2.1. Here we measure similarity through cosine distance instead of the overlap of words. The similarity values are much higher than the previous metric, likely due to the curse of dimensionality, where distance metrics begin to break down as you add dimensions. However, the same general pattern is present: Swedish publications change more and at a greater pace than their Finnish counterparts. Now that we have some reassurance that these feature vectors make sense, we can continue with a more direct comparison of the evolutions of Finnish and Swedish texts.
similarity = [1-spatial.distance.cosine(fin.allFeatize[0], fin.allFeatize[i]) for i in range(len(fin.allFeatize))]
plt.plot(finYears, similarity, label="Finnish")
similarity = [1-spatial.distance.cosine(swe.allFeatize[0], swe.allFeatize[i]) for i in range(len(swe.allFeatize))]
plt.plot(sweYears, similarity, label="Swedish")
plt.title("Similarity to first decade over time")
plt.legend()
plt.show()
2.2.2 Comparing Finnosvenka and Swedish Evolution¶
In the previous section, we computed the top 250 words for each langauge individually. This means that the feature vectors lived in different vector spaces for each langauge. Here, we build shared feature vectors by computing the top 250 words across both languages. Now, the feature vectors for each decade across Finnosvenka and Swedish texts can be directly compared. To do so, we project the 250-dimension vectors into 2D space using PCA. The two dimensions remaining capture the greatest variance in the vectors and allow us to make a visual inspection of the relationship between decades and language, which we conduct below.
# Find top 250 most frequent words across both langauges, based on frequency
totalSwed = sum([s[1] for s in swe.topWordsCounter])
freqsSwed = []
for c in swe.topWordsCounter:
freqsSwed += [(c[0], c[1]/totalSwed)]
totalFin = sum([s[1] for s in fin.topWordsCounter])
freqsFin = []
for c in fin.topWordsCounter:
freqsFin += [(c[0], c[1]/totalFin)]
# Build a Counter that combines the frequences from both languages
combined = Counter()
for word in freqsSwed:
combined[word[0]] += word[1]
for word in freqsFin:
combined[word[0]] += word[1]
# Based on the top 250 shared words, build the vector of frequencies for each decade
sweAllFeatize = []
for counter in list(swe.allCounters.values()):
lenDoc = sum(counter.values())
featize = np.array([counter[k] for k,v in combined.items()])
featize = np.divide(featize, lenDoc)
sweAllFeatize += [featize]
finAllFeatize = []
for counter in list(fin.allCounters.values()):
lenDoc = sum(counter.values())
featize = np.array([counter[k] for k,v in combined.items()])
featize = np.divide(featize, lenDoc)
finAllFeatize += [featize]
pca = PCA(n_components=4)
pca_result= pca.fit_transform(sweAllFeatize + finAllFeatize)
numSweDecades = len(sweAllFeatize)
x_swe = pca_result[:numSweDecades, 0]
x_fin = pca_result[numSweDecades:,0]
y_swe = pca_result[:numSweDecades,1]
y_fin = pca_result[numSweDecades:,1]
plt.figure(figsize=(15,10))
plt.scatter(x_swe, y_swe, label="Swedish")
for i in range(len(list(swe.allCounters.keys()))):
plt.annotate(list(swe.allCounters.keys())[i], (x_swe[i], y_swe[i]))
plt.scatter(x_fin, y_fin, label="Finnish")
for i in range(len(list(fin.allCounters.keys()))):
plt.annotate(list(fin.allCounters.keys())[i], (x_fin[i], y_fin[i]))
plt.legend()
plt.title("Projection of Feature Vectors")
plt.show()

There are a few trends that we can analyze within the above graph. First, we see that in both Finnosvenka and Swedish, the 18th century decades seem to be oddballs. They are both off to the left hand side of the graph, with the Finnosvenka points being slightly tighter than the Swedish decades. Many language corpora show this trend of the oldest publications being the most different, likely due to the modernization that would come in later years. However it’s also important to note that the OCR system used to create both corpora is nowhere near as effective for earlier years, meaning there could simply be more noise in the early decades that create excessive differences in their contents. However, the effects of the limited OCR should be mitigated here because we are using only the top 250 most common words, which would likely have a better OCR success rate. Curiously, the one exception to this trend is the 1760 decade in Swedish texts, which is cloer to later publishings.
The next trend is the clear progression of both languages towards more negative principal component 1 values over time. This suggest some sort of common linguistic evolution, although once again Finnovsenka texts seems to exhibit less rapid changes. The Finnosvenka texts also exhibit less variance in the second principal component. A more detailed analysis of the word choice causing this evolution is the next step towards understanding this common trend, and as such we turn to analyzing specific words in the next section.
3. Word Analysis¶
Now that we’ve analyzed the broader trends of the texts, we’ll look at specific words and see how their usage over time compares across langauges. This will provide a more detailed analysis of the cultural differences between the languages.
3.1 Words Unique to Each Corpus¶
The simplest place to start is to look at words that occur in Finnosvenka text but not Swedish text, and vice versa. This is a good indicator of what topics each linguistic group might focus on that the other doesn’t. A lot of cities in each country (Sweden vs. Finland) show up in the following lists. Some examples incldue:
Cities: Helsignfors and Malmö are cities in Finland and Sweden, respectively, and don’t show up in the other corpus.
Historical Ties: The Finnosvenka texts mentions the Russian city of St. Petersburg, which makes sense considering Finland’s historical ties to Russia.
Currency: The Swedish kronor (the name of the Swedish currency) is mentioned only the Swedish text.
fin.topWordsTotal = [s.lower() for s in fin.topWordsTotal]
print("In Finnosvenka but not Swedish: \n\t", set(fin.topWordsTotal).difference(swe.topWordsTotal))
print("\nIn Swedish but not Finnosvenka: \n\t", set(swe.topWordsTotal).difference(fin.topWordsTotal))
In Finnosvenka but not Swedish:
{'gjort', 'stad', 'mark', 'gar', 'hvilket', 'helsingfors', 'huru', 'namn', 'regeringen', 'denne', 'land', 'afseende', 'böra', 'emedan', 'åter', 'finland', 'kop', 'finlands', 'måste', 'vill', 'bet', 'london', 'ganska', 'manad', 'åbo', 'alltid', 'voro', 'sådant', 'sta', 'ifrån', 'gärden', 'wasa', 'mcd', 'sade', 'vore', 'densamma', 'län', 'for', 'penni', 'finska', 'emellan', 'landet', 'också', 'amp', 'fom', 'wiborg', 'äbo', 'petersburg', 'abo', 'johan', 'dig', 'först', 'lör', 'borde', 'fall'}
In Swedish but not Finnosvenka:
{'parti', 'herrar', 'goda', 'kronor', 'fru', 'stadens', 'salu', 'billiga', 'dito', 'mäste', 'december', 'härmed', 'godt', 'finnas', 'hwilket', 'nied', 'andersson', 'ocb', 'carlskrona', 'norra', 'oktober', 'rdr', 'härstädes', 'öre', 'son', 'flera', 'undertecknad', 'kök', 'januari', 'priser', 'emellertid', 'månad', 'hyra', 'kapten', 'derefter', 'göteborg', 'ooh', 'huset', 'nästkommande', 'norrköpings', 'nägon', 'februari', 'afton', 'lund', 'linköping', 'oell', 'afgår', 'sorn', 'lördagen', 'meddelar', 'ali', 'stort', 'norrköping', 'auktion', 'örn', 'sör', 'nästa', 'par', 'lager', 'kongl', 'billigt', 'kontor', 'boktryckeriet', 'ester', 'arbete', 'går', 'plats', 'torget', 'hus', 'malmö', 'tiden'}
3.2 Finnish Loanwords¶
To get a little deeper into the linguistic differences, we look at Finnish words that have been adopted by the Swedish language. We hypothesize that these Finnish loanwords would see greater use in Finnosvenka texts due to the geopgrahic proximity of the group to Finnish speakers (in fact, many Swedish-speaking Finns are likely fluent in Finnish as well). To measure this trend, we look at the relative frequency per 100,000 words of these loanwords across all time for both languages. To see if the frequency of words are statistically significant across Finnosvenka and Swedish texts, we perform a G-test that calculate the probability of the frequencies of a loanword being different across langauges, given the null hypothesis that their frequencies are similar in each language. A value of p < 0.05 allows us to reject the null hypothesis and indicates that there is a statistically significant difference in the way both languages use a given loanword.
sweWordCount = sum([sum(c.values()) for c in swe.allCounters.values()])
finWordCount = sum([sum(c.values()) for c in fin.allCounters.values()])
def getFrequenciesLog(candidates):
for cand in candidates:
finCount = sum([c[cand] for c in fin.allCounters.values()])
sweCount = sum([c[cand] for c in swe.allCounters.values()])
finTotal = sum([sum(c.values()) for c in fin.allCounters.values()])
sweTotal = sum([sum(c.values()) for c in fin.allCounters.values()])
finFreq = (log(finCount+1)-log(finTotal))
sweFreq = (log(sweCount+1)-log(sweTotal))
print("Finnish loanword freq {:s}: \tFinnish: {:4f} \tSwedish: {:4f} \t [{:s}]".format(
cand, finFreq, sweFreq, str(finFreq > sweFreq)
))
def getFreqsDict(candidates):
candidates_d = {k: [] for k in candidates}
for i, cand in enumerate(candidates):
finCount = [c[cand] for c in fin.allCounters.values()]
sweCount = [c[cand] for c in swe.allCounters.values()]
finTotal = [sum(c.values()) for c in fin.allCounters.values()]
sweTotal = [sum(c.values()) for c in fin.allCounters.values()]
finFreqs = [(c[cand])/(sum(c.values()))*100000 for c in fin.allCounters.values()]
sweFreqs = [(c[cand])/(sum(c.values()))*100000 for c in swe.allCounters.values()]
# Average these frequences across all years
finFreq = sum( [(c[cand]) / (sum(c.values()))*100000 for c in fin.allCounters.values()]) / len(fin.allCounters)
sweFreq = sum([(c[cand])/(sum(c.values()))*100000 for c in swe.allCounters.values()]) / len(swe.allCounters)
candidates_d[cand] = (finFreqs, sweFreqs)
# https://wordhoard.northwestern.edu/userman/analysis-comparewords.html
a, b = sum(finCount), sum(sweCount)
c, d = sum(finTotal), sum(sweTotal)
e1 = c * (a + b) / (c + d)
e2 = d * (a + b) / (c + d)
G2 = 2* (a * np.log(a / e1) + b * np.log(b / e2))
p = 1 - stats.chi2.cdf(G2, 1)
# print("G^2 Stat: ", G2)
print("{}. Finnish loanword {:s}: \tFinnish: {:4f} \tSwedish: {:4f} \t{}".format(
i+1, cand, finFreq, sweFreq, "Signfinicant!" if p< 0.05 else ""
))
return candidates_d
cand_freqs = getFreqsDict(["kola", "kova", "pulka", "memma"])
1. Finnish loanword kola: Finnish: 0.620426 Swedish: 0.469006 Signfinicant!
2. Finnish loanword kova: Finnish: 0.011458 Swedish: 0.010739 Signfinicant!
3. Finnish loanword pulka: Finnish: 0.013246 Swedish: 0.005780 Signfinicant!
4. Finnish loanword memma: Finnish: 0.036777 Swedish: 0.000000
/share/apps/anaconda3/2020.02/lib/python3.7/site-packages/ipykernel_launcher.py:37: RuntimeWarning: divide by zero encountered in log
/share/apps/anaconda3/2020.02/lib/python3.7/site-packages/ipykernel_launcher.py:37: RuntimeWarning: invalid value encountered in double_scalars
Kola : translated as “to die.” Adapted from the Finnish word “kuolla,” this is the most common loanword across both languages.
Kova: translated as “money.” Originally from a Finnish expression “kova raha” meaning coins.
Pulka: translated as “sled.” Orignally from a Finnish and Sami (an indigenous group that lives in the north of both countries) word “pulkka”.
Memma: a traditional Finnish Easter pudding, originally called “mämmi” in Finnish. The dessert has supposedly begun to be exported to Sweden, although the frequencies of the word in either corpus can’t back up that statement.
3.3 Tracking the Usage of Loanwords¶
As section 3.2 shows, there are Finnish loanwords that are statistically signifcant in their usage across Finnosvenka and Swedish text. We now pick a few loanwords and track their usage over time to attempt to identify trends in usage between Finnosvenka and Swedish text.
3.3.1 Kola:¶
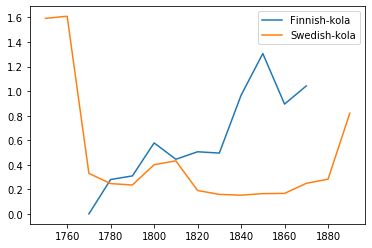
The word “kola” (to die) is the most common loanword across both texts. Other than a curious spike right at the beginning, Swedish texts seem to use the word less frequently than Finnosvenka texts. Around the 1850’s, usage of the word peaks in Finnosvenka texts. A few decades later, the usage of the word in Swedish texts starts to increase as well. The word has other usages in Swedish, including “toffee,” so a more detailed analysis of the context of this word would be necessary to tease apart possible differences in the word meaning. (wiktionary)
candidates_d = getFreqsDict(["kola"])
plt.plot(finYears, candidates_d['kola'][0], label="Finnish-kola")
plt.plot(sweYears, candidates_d['kola'][1], label="Swedish-kola")
plt.legend()
1. Finnish loanword kola: Finnish: 0.620426 Swedish: 0.469006 Signfinicant!
<matplotlib.legend.Legend at 0x7ff2970ef450>
3.3.2 Kova vs. Raha¶
Kova is the loanword that means “money” (“raha” in Finnish), derived from the Finnish phrase “kova raha” that originally means “coins” (quora). In order to test the hypothesis that Finnosvenka texts might directly take Finnish words as well as create loanwords to Swedish, we compare the usage of the words raha and kova.
candidates_d = getFreqsDict(["raha", "kova"])
plt.plot(finYears, candidates_d['raha'][0], label="Finnish-raha")
plt.plot(sweYears, candidates_d['raha'][1], label="Swedish-raha")
plt.plot(finYears, candidates_d['kova'][0], label="Finnish-kova")
plt.plot(sweYears, candidates_d['kova'][1], label="Swedish-kova")
plt.legend()
/share/apps/anaconda3/2020.02/lib/python3.7/site-packages/ipykernel_launcher.py:37: RuntimeWarning: divide by zero encountered in log
/share/apps/anaconda3/2020.02/lib/python3.7/site-packages/ipykernel_launcher.py:37: RuntimeWarning: invalid value encountered in double_scalars
1. Finnish loanword raha: Finnish: 0.012326 Swedish: 0.000000
2. Finnish loanword kova: Finnish: 0.011458 Swedish: 0.010739 Signfinicant!
<matplotlib.legend.Legend at 0x7ff29719e150>
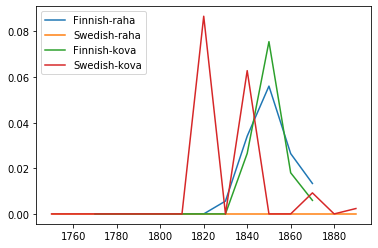
The above graph shows the use of raha and kova in both languages over time. Swedish texts never use the term raha, which makes sense because it is exclusively a Finnish word. In the Finnosvenka texts, usage of both words peak at almost exactly the same time. This could be due to the usage of the full Finnish phrase “kova raha,” or they could be used as synonyms in a certain context. There isn’t enough data to make a conclusion about the usage of raha in either text, but there is a statistically significant difference in the usage of kova in either texts, with the Finnish text using it more often.
3.3.3 Pojke vs. Poika¶
Pojke is the Swedish loanword for the Finnish word poika and is a colloqial word for “boy.” (wiktionary) This is a second example of testing whether Finnosvenka texts bias towards the Swedish of Finnish version of the word.
candidates_d = getFreqsDict(["pojke", "poika"])
plt.plot(finYears, candidates_d['pojke'][0], label="Finnish-pojke")
plt.plot(sweYears, candidates_d['pojke'][1], label="Swedish-pojke")
plt.plot(finYears, candidates_d['poika'][0], label="Finnish-poika")
plt.plot(sweYears, candidates_d['poika'][1], label="Swedish-poika")
plt.legend()
1. Finnish loanword pojke: Finnish: 0.290092 Swedish: 0.458642 Signfinicant!
2. Finnish loanword poika: Finnish: 0.111841 Swedish: 0.001719 Signfinicant!
<matplotlib.legend.Legend at 0x7ff2968e5d50>
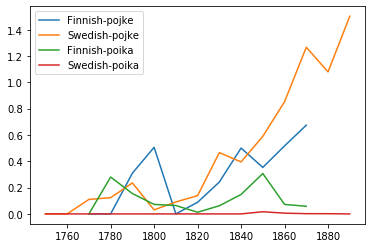
Here we see that the Finnosvenka uses the direct Finnish version ‘poika’ far more than Swedish texts, although both use the Swedish version ‘pojke’ more often. There is a compelling increase in the usage of pojke in Swedish texts just as Finnosvenka texts begin to use it in replacement of poika. So, as Swedish texts begin to use the Swedish version of the word, Finnosvenka texts significantly decrease their usage of ‘poika.’ It’s hard to determine any sort of causal relationship without more etymological details, but this example suggests that ther is a marked relationship between the language of origin and the word’s usage.
4. Future Work¶
Comparing loanwords provides a good calibration for comparing word usage patterns across langauges. To go further with this analysis, we could search for words with the greatest difference in frequency across texts and use this to investicate dialectical differences. We could also create more detailed representation of content words by training word embeddings on subsets of the corpora and comparing their representations.
For every experiment detailed above, we look only at the word frequencies of a newspaper publication. The next step in analyzing the text could be to look at syntatical differences in the publications. The original dataset contains Part-of-Speech and Named Entity tags, along with other annotations, that could be analyzed as well. However the tagging systems used in the SpråkbankenText platform are rather outdated. With the right time and resources, one ambitious project could be to fine-tune present state-of-the-art tagging systems on the Finnosvenka and Swedish texts.
5. Conclusion¶
In conclusion, this project looked at the evolutionary trends of Finnosvenka and Swedish by performing both quantitative and qualitative analyses of word frequency within newspaper publications. We found that Finnish texts exhibited less evolution than their Swedish counterparts, but also adopted more words from the majority Finnish-speaking population. Clearly, cultural and geographic contexts create differences in the two languages, with far more possible avenues of comparison yet to explore.