Twitter Data Collection & Analysis#
Important Update
In 2023, Twitter (now X) dramatically restricted access to its API, effectively ending free academic research access. The code examples below were written when the API was still accessible and are preserved for reference, but they will no longer work without a paid API subscription. See the Twitter Data overview for more details.
In this lesson, we’re going to learn how to analyze and explore Twitter data with the Python/command line tool twarc. We’re specifically going to work with twarc2, which is designed for version 2 of the Twitter API (released in 2020) and the Academic Research track of the Twitter API (released in 2021), which enables researchers to collect tweets from the entire Twitter archive for free.
Twarc was developed by a project called Documenting the Now. The DocNow team develops tools and ethical frameworks for social media research.
Dataset#
[David Foster Wallace]…has become lit-bro shorthand…Make a passing reference to the “David Foster Wallace fanboy” and you can assume the reader knows whom you’re talking about.
—Molly Fischer, “David Foster Wallace, Beloved Author of Bros”
 Source: Giovanni Giovanetti, NYT
Source: Giovanni Giovanetti, NYT
The Twitter conversation that we’re going to explore in this lesson is related to “Wallace bros” — fans of the author David Foster Wallace who are often described as “bros” or, more pointedly, “David Foster Wallace bros.”
For example, in Slate in 2015, Molly Fischer argued that David Foster Wallace’s writing — most famously his novel Infinite Jest — tended to attract a fan base of chauvinistic and misogynistic young men. But other people have defended Wallace’s fans and the author against such charges. What is a “David Foster Wallace bro”? Was DFW himself a “bro”? Who is using this phrase, how often are they using it, and why? We’re going to track this phrase and explore the varied viewpoints in this cultural conversation by analyzing tweets that mention “David Foster Wallace bro.”
Search Queries & Privacy Concerns#
To collect tweets from the Twitter API, we need to make queries, or requests for specific kinds of tweets — e.g., twarc2 search *query*. The simplest kind of query is a keyword search, such as the phrase “David Foster Wallace bro,” which should return any tweet that contains all of these words in any order — twarc2 search "David Foster Wallace bro".
There are many other operators that we can add to a query, which would allow us to collect tweets only from specific Twitter users or locations, or to only collect tweets that meet certain conditions, such as containing an image or being authored by a verified Twitter user. Here’s an excerpted table of search operators taken from Twitter’s documentation about how to build a search query. There are many other operators beyond those included in this table, and I recommend reading through Twitter’s entire web page on this subject.
Search Operator |
Explanation |
|---|---|
keyword |
Matches a keyword within the body of a Tweet. |
“exact phrase match” |
Matches the exact phrase within the body of a Tweet. |
- |
Do NOT match a keyword or operator |
# |
Matches any Tweet containing a recognized hashtag |
from:, to: |
Matches any Tweet from or to a specific user. |
place: |
Matches Tweets tagged with the specified location or Twitter place ID. |
is:reply, is:quote |
Returns only replies or quote tweets. |
is:verified |
Returns only Tweets whose authors are verified by Twitter. |
has:media |
Matches Tweets that contain a media object, such as a photo, GIF, or video, as determined by Twitter. |
has:images, has:videos |
Matches Tweets that contain a recognized URL to an image. |
has:geo |
Matches Tweets that have Tweet-specific geolocation data provided by the Twitter user. |
In this lesson, we will only be collecting tweets that were tweeted by verified users: "David Foster Wallace bro is:verified".
As I discussed in “Users’ Data: Legal & Ethical Considerations,” collecting publicly available tweets is legal, but it still raises a lot of privacy concerns and ethical quandaries — particularly when you re-publish user’s data, as I am in this lesson. To reduce potential harm to Twitter users when re-publishing or citing tweets, it can be helpful to ask for explicit permission from the authors or to focus on tweets that have already been reasonably exposed to the public (e.g., tweets with many retweets or tweets from verified users), such that re-publishing the content will not unduly increase risk to the user.
Install and Import Libraries#
Because twarc relies on Twitter’s API, we need to apply for a Twitter developer account and create a Twitter application before we can use it. You can find instructions for the application process in “Twitter API Set Up.”
If you haven’t done so already, you need to install twarc and configure twarc with your bearer token and/or API keys.
#!pip install twarc
#!twarc2 configure
To make an interactive plot, we’re also going to install the package plotly.
!pip install plotly
Then we’re going to import plotly as well as pandas
import plotly.express as px
import pandas as pd
pd.options.display.max_colwidth = 400
pd.options.display.max_columns = 90
Get Tweet Counts#
The first thing we’re going to do is retrieve “tweet counts” — that is, retrieve the number of tweets that included the phrase “David Foster Wallace bro” each day in Twitter’s history.
The tweet counts API endpoint is a convenient feature of the v2 API (first introduced in 2021) that allows us to get a sense of how many tweets will be returned for a given query before we actually collect all the tweets that match the query. We won’t get the text of the tweets or the users who tweeted the tweets or any other relevant data. We will simply get the number of tweets that match the query. This is helpful because we might be able to see that the search query “Wallace” matches too many tweets, which would encourage us to narrow our search by modifying the query.
The tweet counts API endpoint is perhaps even more useful for research projects that are primarily interested in tracking the volume of a Twitter conversation over time. In this case, tweet counts enable a researcher to retrieve this information in a way that’s faster and easier than retrieving all tweets and relevant metadata.
To get tweet counts from Twitter’s entire history with twarc2, we will use twarc2 counts followed by a search query.
We will also use the flag --csv because we want to output the data as a CSV, the flag --archive because we’re working with the Academic Research track of the Twitter API and want access to the full archive, and the flag --granularity day to get tweet counts per day (other options include hour and minute — you can see more in twarc’s documentation). Finally, we write the data to a CSV file.
!twarc2 counts "David Foster Wallace bro is:verified" --csv --archive --granularity day > twitter-data/tweet-counts.csv
We can read in this CSV file with pandas, parse the date columns, and sort from earliest to latest. The code below is largely borrowed from Ed Summers. Thanks, Ed!
Pandas Review
Do you need a refresher or introduction to the Python data analysis library Pandas? Be sure to check out Pandas Basics (1-3) in this textbook!
# Code borrowed from Ed Summers
# https://github.com/edsu/notebooks/blob/master/Black%20Lives%20Matter%20Counts.ipynb
# Read in CSV as DataFrame
tweet_counts_df = pd.read_csv('twitter-data/tweet-counts.csv', parse_dates=['start', 'end'])
# Sort values by earliest date
tweet_counts_df = tweet_counts_df.sort_values('start')
tweet_counts_df
| start | end | day_count | |
|---|---|---|---|
| 5735 | 2006-03-21 00:00:00+00:00 | 2006-03-22 00:00:00+00:00 | 0 |
| 5736 | 2006-03-22 00:00:00+00:00 | 2006-03-23 00:00:00+00:00 | 0 |
| 5737 | 2006-03-23 00:00:00+00:00 | 2006-03-24 00:00:00+00:00 | 0 |
| 5738 | 2006-03-24 00:00:00+00:00 | 2006-03-25 00:00:00+00:00 | 0 |
| 5739 | 2006-03-25 00:00:00+00:00 | 2006-03-26 00:00:00+00:00 | 0 |
| ... | ... | ... | ... |
| 26 | 2021-12-19 00:00:00+00:00 | 2021-12-20 00:00:00+00:00 | 0 |
| 27 | 2021-12-20 00:00:00+00:00 | 2021-12-21 00:00:00+00:00 | 0 |
| 28 | 2021-12-21 00:00:00+00:00 | 2021-12-22 00:00:00+00:00 | 0 |
| 29 | 2021-12-22 00:00:00+00:00 | 2021-12-23 00:00:00+00:00 | 0 |
| 30 | 2021-12-23 00:00:00+00:00 | 2021-12-23 14:32:00+00:00 | 0 |
5757 rows × 3 columns
Then we can make a quick plot of tweets per day with plotly
# Code borrowed from Ed Summers
# https://github.com/edsu/notebooks/blob/master/Black%20Lives%20Matter%20Counts.ipynb
# Make a line plot from the DataFrame and specify x and y axes, axes titles, and plot title
figure = px.line(tweet_counts_df, x='start', y='day_count',
labels={'start': 'Time', 'day_count': 'Tweets per Day'},
title= 'DFW Bro Tweets'
)
figure.show()
With a plotly line chart, we can hover over points to see more information, and we can use the tool bar in the upper right corner to zoom or pan on different parts of the graph. We can also press the camera button to download an image of the graph at any pan or zoom level.
To return to the original view, double-click on the plot.
Get Tweets (Standard Track)#
To actually collect tweets and their associated metadata, we can use the command twarc2 search and insert a query.
Here we’re going to search for any tweets that mention the words “David Foster Wallace bro” and were tweeted by verified accounts in the past week. By default, twarc2 search will use the standard track of the Twitter API, which only collects tweets from the past week.
!twarc2 search "David Foster Wallace is:verified"
{"data": [{"entities": {"annotations": [{"start": 40, "end": 59, "probability": 0.961, "type": "Person", "normalized_text": "David Foster Wallace"}]}, "source": "Twitter for iPhone", "conversation_id": "1473826748169175048", "text": "\u201cEvery love story is a ghost story.\u201c\u00a0\n- David Foster Wallace", "created_at": "2021-12-23T01:24:13.000Z", "lang": "en", "reply_settings": "everyone", "author_id": "90573676", "id": "1473826748169175048", "possibly_sensitive": false, "public_metrics": {"retweet_count": 13, "reply_count": 1, "like_count": 55, "quote_count": 2}, "context_annotations": [{"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}, {"domain": {"id": "54", "name": "Musician", "description": "A musician in the world, like Adele or Bob Dylan"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}, {"domain": {"id": "67", "name": "Interests and Hobbies", "description": "Interests, opinions, and behaviors of individuals, groups, or cultures; like Speciality Cooking or Theme Parks"}, "entity": {"id": "1278071502840066048", "name": "Paranormal"}}]}, {"entities": {"annotations": [{"start": 32, "end": 51, "probability": 0.6432, "type": "Person", "normalized_text": "David Foster Wallace"}], "urls": [{"start": 137, "end": 160, "url": "https://t.co/uP4U30fkqv", "expanded_url": "https://www.backstage.com/magazine/article/voiceover-casting-68077/?utm_campaign=organic&utm_content=casting%2Clink%2Cstock-misc%2Ctalent%2Cvoiceover&utm_medium=social&utm_source=twitter", "display_url": "backstage.com/magazine/artic\u2026"}]}, "source": "Sprout Social", "conversation_id": "1473762018855370755", "text": "From a short film adaptation of David Foster Wallace Story to a feature film and everything in between, here\u2019s what\u2019s casting this week. https://t.co/uP4U30fkqv", "created_at": "2021-12-22T21:07:01.000Z", "lang": "en", "reply_settings": "everyone", "author_id": "19920585", "id": "1473762018855370755", "possibly_sensitive": false, "public_metrics": {"retweet_count": 0, "reply_count": 0, "like_count": 0, "quote_count": 0}, "context_annotations": [{"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}, {"domain": {"id": "54", "name": "Musician", "description": "A musician in the world, like Adele or Bob Dylan"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}]}, {"source": "Twitter Web App", "conversation_id": "1473587774821437441", "entities": {"mentions": [{"start": 0, "end": 11, "username": "glennndiaz", "id": "917615998047367168"}]}, "text": "@glennndiaz Hahahaha di ko pa nga binabasa Wikipedia page niya. Before I read The Corrections, akala ko iisa lang sila ni David Foster Wallace hahahaha", "created_at": "2021-12-22T10:06:25.000Z", "lang": "tl", "in_reply_to_user_id": "917615998047367168", "reply_settings": "everyone", "author_id": "37662244", "id": "1473595773400981504", "possibly_sensitive": false, "referenced_tweets": [{"type": "replied_to", "id": "1473591381436162052"}], "public_metrics": {"retweet_count": 0, "reply_count": 0, "like_count": 0, "quote_count": 0}, "context_annotations": [{"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}, {"domain": {"id": "54", "name": "Musician", "description": "A musician in the world, like Adele or Bob Dylan"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}]}, {"entities": {"annotations": [{"start": 16, "end": 35, "probability": 0.7984, "type": "Person", "normalized_text": "david foster wallace"}, {"start": 54, "end": 65, "probability": 0.9346, "type": "Person", "normalized_text": "david foster"}], "mentions": [{"start": 3, "end": 14, "username": "el_fodongo", "id": "966631615"}]}, "source": "Twitter for iPhone", "conversation_id": "1473360294898548738", "text": "RT @el_fodongo: david foster wallace's dog was called david foster gromit", "created_at": "2021-12-21T18:30:42.000Z", "lang": "en", "reply_settings": "everyone", "author_id": "86101978", "id": "1473360294898548738", "possibly_sensitive": false, "referenced_tweets": [{"type": "retweeted", "id": "1392179447051165696"}], "public_metrics": {"retweet_count": 192, "reply_count": 0, "like_count": 0, "quote_count": 0}, "context_annotations": [{"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}, {"domain": {"id": "54", "name": "Musician", "description": "A musician in the world, like Adele or Bob Dylan"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}]}, {"entities": {"annotations": [{"start": 16, "end": 35, "probability": 0.7984, "type": "Person", "normalized_text": "david foster wallace"}, {"start": 54, "end": 65, "probability": 0.9346, "type": "Person", "normalized_text": "david foster"}], "mentions": [{"start": 3, "end": 14, "username": "el_fodongo", "id": "966631615"}]}, "source": "Twitter Web App", "conversation_id": "1473359224453623808", "text": "RT @el_fodongo: david foster wallace's dog was called david foster gromit", "created_at": "2021-12-21T18:26:27.000Z", "lang": "en", "reply_settings": "everyone", "author_id": "76718852", "id": "1473359224453623808", "possibly_sensitive": false, "referenced_tweets": [{"type": "retweeted", "id": "1392179447051165696"}], "public_metrics": {"retweet_count": 192, "reply_count": 0, "like_count": 0, "quote_count": 0}, "context_annotations": [{"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}, {"domain": {"id": "54", "name": "Musician", "description": "A musician in the world, like Adele or Bob Dylan"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}]}, {"entities": {"annotations": [{"start": 84, "end": 103, "probability": 0.9894, "type": "Person", "normalized_text": "David Foster Wallace"}, {"start": 109, "end": 124, "probability": 0.8558, "type": "Person", "normalized_text": "\u00d3scar Villasante"}], "mentions": [{"start": 3, "end": 19, "username": "Notodofilmfest_", "id": "161988497"}, {"start": 49, "end": 63, "username": "camaraabierta", "id": "52823380"}]}, "source": "Twitter for iPhone", "conversation_id": "1473292247873593345", "text": "RT @Notodofilmfest_: \u2728Premio al Mejor Documental\u2728@camaraabierta\n\"Peque\u00f1o Homenaje a David Foster Wallace\" de \u00d3scar Villasante\nhttps://t.co/\u2026", "created_at": "2021-12-21T14:00:18.000Z", "lang": "es", "reply_settings": "everyone", "author_id": "52823380", "id": "1473292247873593345", "possibly_sensitive": false, "referenced_tweets": [{"type": "retweeted", "id": "1473269378565160974"}], "public_metrics": {"retweet_count": 1, "reply_count": 0, "like_count": 0, "quote_count": 0}, "context_annotations": [{"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}, {"domain": {"id": "54", "name": "Musician", "description": "A musician in the world, like Adele or Bob Dylan"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}]}, {"source": "Twitter for iPhone", "conversation_id": "1472984031864279045", "entities": {"mentions": [{"start": 0, "end": 14, "username": "TomA3aenssens", "id": "1189576208"}, {"start": 15, "end": 30, "username": "WimOosterlinck", "id": "53060760"}]}, "text": "@TomA3aenssens @WimOosterlinck De auteur die de doorslag zou geven, is David Foster Wallace, maar die staat bij de fictie.", "created_at": "2021-12-20T17:54:22.000Z", "lang": "nl", "in_reply_to_user_id": "1189576208", "reply_settings": "everyone", "author_id": "292945752", "id": "1472988761785049090", "possibly_sensitive": false, "referenced_tweets": [{"type": "replied_to", "id": "1472987840288116740"}], "public_metrics": {"retweet_count": 0, "reply_count": 0, "like_count": 3, "quote_count": 0}, "context_annotations": [{"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}, {"domain": {"id": "54", "name": "Musician", "description": "A musician in the world, like Adele or Bob Dylan"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}]}, {"entities": {"annotations": [{"start": 46, "end": 57, "probability": 0.7361, "type": "Person", "normalized_text": "Bill Shankly"}, {"start": 60, "end": 79, "probability": 0.9075, "type": "Person", "normalized_text": "David Foster Wallace"}, {"start": 82, "end": 97, "probability": 0.9925, "type": "Person", "normalized_text": "Marina Tsvetaeva"}, {"start": 100, "end": 105, "probability": 0.9963, "type": "Person", "normalized_text": "Eminem"}, {"start": 112, "end": 125, "probability": 0.9834, "type": "Person", "normalized_text": "Kenny Dalglish"}], "urls": [{"start": 169, "end": 192, "url": "https://t.co/rirr55pD5O", "expanded_url": "https://www.amazon.co.uk/gp/aw/d/1781724253/", "display_url": "amazon.co.uk/gp/aw/d/178172\u2026"}]}, "source": "Twitter for iPhone", "conversation_id": "1472930896223383559", "text": "Find me another book that assembles a cast of Bill Shankly, David Foster Wallace, Marina Tsvetaeva, Eminem, and Kenny Dalglish. A unique stocking filler, or so I hear.\n\nhttps://t.co/rirr55pD5O", "created_at": "2021-12-20T14:04:26.000Z", "lang": "en", "reply_settings": "everyone", "author_id": "2435437579", "id": "1472930896223383559", "possibly_sensitive": false, "public_metrics": {"retweet_count": 1, "reply_count": 0, "like_count": 1, "quote_count": 0}, "context_annotations": [{"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}, {"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "1095842197574844416", "name": "Kenny Dalglish"}}, {"domain": {"id": "54", "name": "Musician", "description": "A musician in the world, like Adele or Bob Dylan"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}, {"domain": {"id": "92", "name": "Sports Personality", "description": "A Sports Personality like 'Skip Bayless'"}, "entity": {"id": "1095842197574844416", "name": "Kenny Dalglish"}}, {"domain": {"id": "92", "name": "Sports Personality", "description": "A Sports Personality like 'Skip Bayless'"}, "entity": {"id": "1202239681422774272", "name": "Sports icons"}}, {"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "808389766676811780", "name": "Eminem", "description": "Eminem"}}, {"domain": {"id": "54", "name": "Musician", "description": "A musician in the world, like Adele or Bob Dylan"}, "entity": {"id": "808389766676811780", "name": "Eminem", "description": "Eminem"}}, {"domain": {"id": "55", "name": "Music Genre", "description": "A category for a musical style, like Pop, Rock, or Rap"}, "entity": {"id": "810937888334487552", "name": "Rap", "description": "Hip-Hop/Rap"}}]}, {"source": "Twitter for Android", "conversation_id": "1472600656787742725", "entities": {"mentions": [{"start": 0, "end": 13, "username": "george_salis", "id": "1357934563838812161"}, {"start": 14, "end": 30, "username": "TheLastSisyphus", "id": "340072715"}], "urls": [{"start": 52, "end": 75, "url": "https://t.co/nLbntaS24J", "expanded_url": "https://sites.utexas.edu/ransomcentermagazine/2016/01/29/david-foster-wallace-and-20-years-of-infinite-jest/", "display_url": "sites.utexas.edu/ransomcenterma\u2026"}]}, "text": "@george_salis @TheLastSisyphus Also something here. https://t.co/nLbntaS24J", "created_at": "2021-12-19T17:58:24.000Z", "lang": "en", "in_reply_to_user_id": "1357934563838812161", "reply_settings": "everyone", "author_id": "17853057", "id": "1472627388911538176", "possibly_sensitive": false, "referenced_tweets": [{"type": "replied_to", "id": "1472604673962037250"}], "public_metrics": {"retweet_count": 0, "reply_count": 2, "like_count": 1, "quote_count": 0}}, {"entities": {"annotations": [{"start": 33, "end": 52, "probability": 0.9895, "type": "Person", "normalized_text": "David Foster Wallace"}], "urls": [{"start": 90, "end": 113, "url": "https://t.co/poOtnWcmsc", "expanded_url": "https://twitter.com/velazquera/status/1471895454103314433", "display_url": "twitter.com/velazquera/sta\u2026"}]}, "source": "Twitter for iPhone", "conversation_id": "1471945897038729217", "text": "Estoy tan feliz: mi ensayo sobre David Foster Wallace est\u00e1 incluido en esta publicaci\u00f3n \ud83e\udd70 https://t.co/poOtnWcmsc", "created_at": "2021-12-17T20:50:23.000Z", "lang": "es", "reply_settings": "everyone", "author_id": "45840741", "id": "1471945897038729217", "possibly_sensitive": false, "referenced_tweets": [{"type": "quoted", "id": "1471895454103314433"}], "public_metrics": {"retweet_count": 1, "reply_count": 2, "like_count": 18, "quote_count": 0}, "context_annotations": [{"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}, {"domain": {"id": "54", "name": "Musician", "description": "A musician in the world, like Adele or Bob Dylan"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}, {"domain": {"id": "65", "name": "Interests and Hobbies Vertical", "description": "Top level interests and hobbies groupings, like Food or Travel"}, "entity": {"id": "1280550787207147521", "name": "Arts & culture"}}]}, {"entities": {"annotations": [{"start": 34, "end": 48, "probability": 0.7699, "type": "Organization", "normalized_text": "Emerson College"}, {"start": 51, "end": 70, "probability": 0.8445, "type": "Person", "normalized_text": "David Foster Wallace"}], "mentions": [{"start": 0, "end": 13, "username": "slentine2010", "id": "1681097215"}], "urls": [{"start": 88, "end": 111, "url": "https://t.co/LYHGQfxvgC", "expanded_url": "https://www.esquire.com/entertainment/movies/a15334056/paul-thomas-anderson-david-foster-wallace-reddit/", "display_url": "esquire.com/entertainment/\u2026"}]}, "source": "Twitter Web App", "conversation_id": "1471842268072095754", "text": "@slentine2010 And when he went to Emerson College, David Foster Wallace was his teacher https://t.co/LYHGQfxvgC", "created_at": "2021-12-17T18:06:28.000Z", "lang": "en", "in_reply_to_user_id": "1681097215", "reply_settings": "everyone", "author_id": "29092660", "id": "1471904645836591104", "possibly_sensitive": false, "referenced_tweets": [{"type": "replied_to", "id": "1471842268072095754"}], "public_metrics": {"retweet_count": 0, "reply_count": 1, "like_count": 1, "quote_count": 0}, "context_annotations": [{"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}, {"domain": {"id": "54", "name": "Musician", "description": "A musician in the world, like Adele or Bob Dylan"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}]}, {"entities": {"annotations": [{"start": 56, "end": 71, "probability": 0.9829, "type": "Person", "normalized_text": "Jeffrey Lawrence"}, {"start": 76, "end": 82, "probability": 0.3995, "type": "Organization", "normalized_text": "US Open"}, {"start": 85, "end": 104, "probability": 0.9748, "type": "Person", "normalized_text": "David Foster Wallace"}], "mentions": [{"start": 29, "end": 44, "username": "Ariz_Quarterly", "id": "789573528458670080"}], "urls": [{"start": 146, "end": 169, "url": "https://t.co/iham6vILfC", "expanded_url": "https://bit.ly/3q8k8ly", "display_url": "bit.ly/3q8k8ly", "images": [{"url": "https://pbs.twimg.com/news_img/1471231338040680452/xtA_HeTF?format=jpg&name=orig", "width": 600, "height": 910}, {"url": "https://pbs.twimg.com/news_img/1471231338040680452/xtA_HeTF?format=jpg&name=150x150", "width": 150, "height": 150}], "status": 200, "title": "Article", "description": "In lieu of an abstract, here is a brief excerpt of the content: Postmodernist discourses are often exclusionary even when, having been accused of lacking concrete relevance, they call attention to and appropriate the experience of \u201cdifference\u201d and \u201cotherness\u201d in order to provide themselves with oppositional political meaning, legitimacy, and immediacy. Very few African-American intellectuals have talked or written about postmodernism. Recently at a dinner party, I talked about trying to grapple with the", "unwound_url": "https://muse.jhu.edu/article/27283?utm_source=twitter&utm_medium=social&utm_campaign=arq121721&utm_content=JHUP"}, {"start": 170, "end": 193, "url": "https://t.co/SrLkMELsYj", "expanded_url": "https://twitter.com/JHUPress/status/1471857768462176268/photo/1", "display_url": "pic.twitter.com/SrLkMELsYj"}]}, "source": "Hootsuite Inc.", "conversation_id": "1471857768462176268", "attachments": {"media_keys": ["3_1471857766570549250"]}, "text": "OUT NOW: The latest issue of @Ariz_Quarterly, including Jeffrey Lawrence's \"US Open? David Foster Wallace, Tennis and the Crisis of Meritocracy\": https://t.co/iham6vILfC https://t.co/SrLkMELsYj", "created_at": "2021-12-17T15:00:12.000Z", "lang": "en", "reply_settings": "everyone", "author_id": "29731124", "id": "1471857768462176268", "possibly_sensitive": false, "public_metrics": {"retweet_count": 0, "reply_count": 0, "like_count": 0, "quote_count": 0}, "context_annotations": [{"domain": {"id": "3", "name": "TV Shows", "description": "Television shows from around the world"}, "entity": {"id": "10044747023", "name": "US Open"}}, {"domain": {"id": "6", "name": "Sports Event"}, "entity": {"id": "1398019721518219264", "name": "U.S. Open Tennis"}}, {"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}, {"domain": {"id": "54", "name": "Musician", "description": "A musician in the world, like Adele or Bob Dylan"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}]}, {"source": "Twitter for iPhone", "conversation_id": "1471808169630392327", "text": "\u201cLa verit\u00e0 ti render\u00e0 libero. Ma solo quando avr\u00e0 finito con te\u201d\n\nDavid Foster Wallace, Infinite Jest", "created_at": "2021-12-17T11:43:07.000Z", "lang": "it", "reply_settings": "everyone", "author_id": "1311755732782657536", "id": "1471808169630392327", "possibly_sensitive": false, "public_metrics": {"retweet_count": 5, "reply_count": 0, "like_count": 37, "quote_count": 0}, "context_annotations": [{"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}, {"domain": {"id": "54", "name": "Musician", "description": "A musician in the world, like Adele or Bob Dylan"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}]}], "includes": {"users": [{"location": "New York City", "profile_image_url": "https://pbs.twimg.com/profile_images/797105077219639296/sIN2ZMVs_normal.jpg", "created_at": "2009-11-17T06:00:39.000Z", "pinned_tweet_id": "1239894564149891072", "verified": true, "username": "jerrysaltz", "name": "Jerry Saltz", "protected": false, "description": "Jerry Saltz: Senior Art Critic; New York Magazine. 2018 Pulitzer Prize in Criticism. Author of NYT Best Seller \u201cHow To Be an Artist.\u201d 2-time ASME award winner.", "id": "90573676", "url": "", "public_metrics": {"followers_count": 533796, "following_count": 3991, "tweet_count": 61093, "listed_count": 2343}}, {"profile_image_url": "https://pbs.twimg.com/profile_images/1230605399491043331/u_OcQ5bL_normal.png", "created_at": "2009-02-02T18:20:38.000Z", "pinned_tweet_id": "1461016382120808463", "verified": true, "username": "Backstage", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/VBU3lmc1t6", "expanded_url": "http://www.backstage.com", "display_url": "backstage.com"}]}, "description": {"hashtags": [{"start": 71, "end": 80, "tag": "IGotCast"}]}}, "name": "Backstage", "protected": false, "description": "The most trusted name in casting since 1960. Tweet us with the hashtag #IGotCast and let us know if you've been cast through Backstage!", "id": "19920585", "url": "https://t.co/VBU3lmc1t6", "public_metrics": {"followers_count": 137997, "following_count": 2780, "tweet_count": 76552, "listed_count": 1755}}, {"location": "Philippines", "profile_image_url": "https://pbs.twimg.com/profile_images/1466664667154370565/F8gd8lHJ_normal.jpg", "created_at": "2009-05-04T13:45:10.000Z", "pinned_tweet_id": "1458400249605541893", "verified": true, "username": "jodeszgavilan", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/TOWtr0cvoo", "expanded_url": "https://rappler.com/author/jodesz-gavilan", "display_url": "rappler.com/author/jodesz-\u2026"}]}, "description": {"hashtags": [{"start": 133, "end": 149, "tag": "StopTheKillings"}], "mentions": [{"start": 52, "end": 66, "username": "rapplerdotcom"}, {"start": 67, "end": 79, "username": "newsbreakph"}]}}, "name": "Jodesz Gavilan", "protected": false, "description": "Journalist covering human rights, impunity, etc for @rapplerdotcom @newsbreakph. Host, Newsbreak: Beyond the Stories. Books + OSINT. #StopTheKillings \ud83c\uddf5\ud83c\udded", "id": "37662244", "url": "https://t.co/TOWtr0cvoo", "public_metrics": {"followers_count": 2711, "following_count": 772, "tweet_count": 100313, "listed_count": 66}}, {"location": "Adelaide / Manila", "profile_image_url": "https://pbs.twimg.com/profile_images/1383967272000049156/5oRmdeoJ_normal.jpg", "created_at": "2017-10-10T05:01:17.000Z", "pinned_tweet_id": "1279417624296779776", "verified": false, "username": "glennndiaz", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/EADMN6S6RM", "expanded_url": "http://glenndiaz.ph", "display_url": "glenndiaz.ph"}]}, "description": {"mentions": [{"start": 5, "end": 17, "username": "ateneopress"}, {"start": 28, "end": 42, "username": "UniofAdelaide"}]}}, "name": "Glenn Diaz", "protected": false, "description": "TQO (@ateneopress) PhD cand @UniofAdelaide Anti-imperialist \u262d", "id": "917615998047367168", "url": "https://t.co/EADMN6S6RM", "public_metrics": {"followers_count": 3400, "following_count": 708, "tweet_count": 25599, "listed_count": 10}}, {"location": "mollie.goodfellow@gmail.com", "profile_image_url": "https://pbs.twimg.com/profile_images/1466014663808856065/CgekXjsd_normal.jpg", "created_at": "2009-10-29T16:13:14.000Z", "verified": true, "username": "hansmollman", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/qFKl4ydBYd", "expanded_url": "http://molliegoodfellow.co.uk", "display_url": "molliegoodfellow.co.uk"}]}}, "name": "Mollie Goodfellow", "protected": false, "description": "a writer for many things. cute and precariously employed. it\u2019s probably a joke. she/her.", "id": "86101978", "url": "https://t.co/qFKl4ydBYd", "public_metrics": {"followers_count": 80169, "following_count": 2992, "tweet_count": 85704, "listed_count": 379}}, {"location": "The arboreal dell. (he/him) ", "profile_image_url": "https://pbs.twimg.com/profile_images/1445524623253139462/h_BdjALu_normal.jpg", "created_at": "2012-11-23T18:41:40.000Z", "pinned_tweet_id": "1469967027158802435", "verified": false, "username": "el_fodongo", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/gAIIBvAWyR", "expanded_url": "https://ko-fi.com/timmacgabhann", "display_url": "ko-fi.com/timmacgabhann"}]}, "description": {"mentions": [{"start": 84, "end": 92, "username": "wnbooks"}]}}, "name": "tim, the chancellor of christmas and germany also", "protected": false, "description": "slime man, mulch lord and full-time mayor / wrote CALL HIM MINE & HOW TO BE NOWHERE @wnbooks / i have a v over-zealous block bot, sorry in advance", "id": "966631615", "url": "https://t.co/gAIIBvAWyR", "public_metrics": {"followers_count": 3951, "following_count": 1449, "tweet_count": 22659, "listed_count": 0}}, {"location": "Cardiff/London", "profile_image_url": "https://pbs.twimg.com/profile_images/750985536043638784/YDfIaPP3_normal.jpg", "created_at": "2009-09-23T18:38:17.000Z", "pinned_tweet_id": "1355115824076500992", "verified": true, "username": "tristandross", "entities": {"description": {"mentions": [{"start": 29, "end": 36, "username": "online"}]}}, "name": "Stan Account", "protected": false, "description": "having a laugh correspondent @online", "id": "76718852", "url": "", "public_metrics": {"followers_count": 25204, "following_count": 1067, "tweet_count": 74514, "listed_count": 100}}, {"location": "TVE", "profile_image_url": "https://pbs.twimg.com/profile_images/1342186399211130884/knZ4MAVh_normal.jpg", "created_at": "2009-07-01T19:26:59.000Z", "verified": true, "username": "camaraabierta", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/9FbNCB4LV4", "expanded_url": "http://www.rtve.es/camaraabierta", "display_url": "rtve.es/camaraabierta"}]}, "description": {"hashtags": [{"start": 143, "end": 156, "tag": "Canal24Horas"}], "mentions": [{"start": 12, "end": 17, "username": "rtve"}, {"start": 81, "end": 92, "username": "danisesena"}]}}, "name": "C\u00e1mara abierta", "protected": false, "description": "Programa de @rtve sobre internet como plataforma de creaci\u00f3n. Dirige y presenta: @danisesena. Emisi\u00f3n: S\u00e1bados 08:30h 16:45h y martes 00:45 en #Canal24Horas", "id": "52823380", "url": "https://t.co/9FbNCB4LV4", "public_metrics": {"followers_count": 20363, "following_count": 1112, "tweet_count": 4238, "listed_count": 538}}, {"location": "La red", "profile_image_url": "https://pbs.twimg.com/profile_images/1341417142487576579/tdwXlqkF_normal.jpg", "created_at": "2010-07-02T09:05:50.000Z", "pinned_tweet_id": "1473262330859429894", "verified": false, "username": "Notodofilmfest_", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/rVtgyqbvOl", "expanded_url": "https://linktr.ee/notodofilmfest", "display_url": "linktr.ee/notodofilmfest"}]}, "description": {"mentions": [{"start": 11, "end": 22, "username": "la_fabrica"}, {"start": 25, "end": 38, "username": "fesserjavier"}]}}, "name": "Notodofilmfest", "protected": false, "description": "Creado por @la_fabrica y @fesserjavier Notodofilmfest21 \ud83d\ude80 20/12 Gala de entrega de premios", "id": "161988497", "url": "https://t.co/rVtgyqbvOl", "public_metrics": {"followers_count": 10313, "following_count": 558, "tweet_count": 9429, "listed_count": 299}}, {"profile_image_url": "https://pbs.twimg.com/profile_images/1349413607403098117/Y_PkYFLR_normal.jpg", "created_at": "2011-05-04T14:10:06.000Z", "verified": true, "username": "jdceulaer", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/EjGthWzarD", "expanded_url": "http://www.demorgen.be", "display_url": "demorgen.be"}]}, "description": {"mentions": [{"start": 45, "end": 53, "username": "mboudry"}]}}, "name": "Jo\u00ebl De Ceulaer", "protected": false, "description": "Journalist / \u2018Eerste hulp bij pandemie' (met @mboudry, 2021) / \u2018De tragiek van de macht\u2019 (2020) / 'Hoera! De democratie is niet perfect' (2019)", "id": "292945752", "url": "https://t.co/EjGthWzarD", "public_metrics": {"followers_count": 56565, "following_count": 2129, "tweet_count": 72788, "listed_count": 444}}, {"location": "Antwerpen, Belgi\u00eb", "profile_image_url": "https://pbs.twimg.com/profile_images/1452300902350655488/4iukPsHy_normal.jpg", "created_at": "2013-02-17T13:46:33.000Z", "pinned_tweet_id": "1294333815255638021", "verified": false, "username": "TomA3aenssens", "entities": {"description": {"hashtags": [{"start": 67, "end": 82, "tag": "Triggerwarning"}]}}, "name": "Kerstronk Adriaenssens \ud83d\udc45\ud83e\udd1f\ud83c\udfff", "protected": false, "description": "\u2018vuilblond en proper rechts\u2019 Antwerpen, Antwaarps \u00e9n Antwerp ! \ud83d\udd34\u26aa\ufe0f #Triggerwarning !", "id": "1189576208", "url": "", "public_metrics": {"followers_count": 3160, "following_count": 1881, "tweet_count": 55698, "listed_count": 8}}, {"profile_image_url": "https://pbs.twimg.com/profile_images/1280751248006885377/v9YWpADl_normal.jpg", "created_at": "2009-07-02T13:24:22.000Z", "pinned_tweet_id": "1442908778890883072", "verified": false, "username": "WimOosterlinck", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/dvvz9avo2m", "expanded_url": "http://wimoosterlinck.be", "display_url": "wimoosterlinck.be"}]}, "description": {"hashtags": [{"start": 44, "end": 64, "tag": "ikwildegeenkinderen"}, {"start": 65, "end": 76, "tag": "drieboeken"}]}}, "name": "Wim Oosterlinck \ud83c\udf99", "protected": false, "description": "radio - podcast - film - boeken - wijs volk #ikwildegeenkinderen #drieboeken", "id": "53060760", "url": "https://t.co/dvvz9avo2m", "public_metrics": {"followers_count": 57957, "following_count": 381, "tweet_count": 16487, "listed_count": 176}}, {"location": "Sheffield, UK", "profile_image_url": "https://pbs.twimg.com/profile_images/1463200677577084931/A9XtZIPd_normal.jpg", "created_at": "2014-04-09T13:09:24.000Z", "pinned_tweet_id": "1465959871011074050", "verified": true, "username": "BenWilko85", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/UMQgu99gKl", "expanded_url": "http://theguardian.com/profile/ben-wilkinson", "display_url": "theguardian.com/profile/ben-wi\u2026"}]}, "description": {"mentions": [{"start": 83, "end": 94, "username": "SerenBooks"}, {"start": 128, "end": 140, "username": "LivUniPress"}]}}, "name": "Ben Wilkinson", "protected": false, "description": "Writer, poet, foolhardy critic. Poems: Way More Than Luck (2018), Same Difference (@SerenBooks, 2022). Criticism: Don Paterson (@LivUniPress, 2021).", "id": "2435437579", "url": "https://t.co/UMQgu99gKl", "public_metrics": {"followers_count": 2153, "following_count": 1320, "tweet_count": 5450, "listed_count": 20}}, {"location": "Sydney", "profile_image_url": "https://pbs.twimg.com/profile_images/1421821650366918656/S9sIijlN_normal.jpg", "created_at": "2008-12-03T23:35:17.000Z", "pinned_tweet_id": "1466212849865224192", "verified": true, "username": "mclayfield", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/FjTEjwA8h6", "expanded_url": "http://www.matthewclayfield.com/", "display_url": "matthewclayfield.com"}]}}, "name": "Matthew Clayfield", "protected": false, "description": "Lapsed journalist. Occasional critic and screenwriter. Would like to be a full-time novelist.", "id": "17853057", "url": "https://t.co/FjTEjwA8h6", "public_metrics": {"followers_count": 4386, "following_count": 1963, "tweet_count": 14416, "listed_count": 170}}, {"profile_image_url": "https://pbs.twimg.com/profile_images/1357934982866558979/LnmUTf3C_normal.jpg", "created_at": "2021-02-06T06:10:16.000Z", "pinned_tweet_id": "1467198887656054786", "verified": false, "username": "george_salis", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/SDAGWoFwZR", "expanded_url": "https://linktr.ee/georgesalis", "display_url": "linktr.ee/georgesalis"}]}}, "name": "George Salis", "protected": false, "description": "I'm the author of Sea Above, Sun Below. I'm currently working on a maximalist novel titled Morphological Echoes. I run The Collidescope.", "id": "1357934563838812161", "url": "https://t.co/SDAGWoFwZR", "public_metrics": {"followers_count": 473, "following_count": 106, "tweet_count": 1294, "listed_count": 4}}, {"location": "Dept. of Unspecified Services", "profile_image_url": "https://pbs.twimg.com/profile_images/1472014753103028225/33Rr7X2S_normal.jpg", "created_at": "2011-07-22T03:01:12.000Z", "pinned_tweet_id": "1460666619349409800", "verified": false, "username": "TheLastSisyphus", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/oGjVFmtx4k", "expanded_url": "https://linktr.ee/TheLastSisyphusPodcast", "display_url": "linktr.ee/TheLastSisyphu\u2026"}]}}, "name": "C.G.", "protected": false, "description": "Author of PROJECT: SLEEPLESS DREAM | Writer | Teacher | Armchair Philosopher | UFO Crackpot | Hockey coach, player, and fan", "id": "340072715", "url": "https://t.co/oGjVFmtx4k", "public_metrics": {"followers_count": 1542, "following_count": 292, "tweet_count": 5296, "listed_count": 23}}, {"profile_image_url": "https://pbs.twimg.com/profile_images/1472285559989194764/S-ErLzy0_normal.jpg", "created_at": "2009-06-09T13:54:11.000Z", "pinned_tweet_id": "680849321445597185", "verified": true, "username": "Aglaia_Berlutti", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/CnXF4UtMRb", "expanded_url": "http://www.aglaiaberlutti.com", "display_url": "aglaiaberlutti.com"}]}}, "name": "Aglaia Berlutti", "protected": false, "description": "Bruja y hereje. A veces grosera y quiz\u00e1 demente. Fot\u00f3grafa por pasi\u00f3n, amante de las palabras por convicci\u00f3n. Firme creyente en el poder del pensamiento libre.", "id": "45840741", "url": "https://t.co/CnXF4UtMRb", "public_metrics": {"followers_count": 28510, "following_count": 7146, "tweet_count": 364749, "listed_count": 333}}, {"location": "Caracas", "profile_image_url": "https://pbs.twimg.com/profile_images/1472157338656288772/aJgA76-t_normal.jpg", "created_at": "2016-11-08T14:59:11.000Z", "pinned_tweet_id": "1076067402289434624", "verified": false, "username": "velazquera", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/cGCgRnNTtp", "expanded_url": "https://anamariavelazquezanderson.blogspot.com/", "display_url": "anamariavelazquezanderson.blogspot.com"}]}}, "name": "Ana Mar\u00eda Vel\u00e1zquez Anderson", "protected": false, "description": "Profa de Literatura Universidad Metropolitana.\nGender studies\nEscritora.", "id": "796004142007324672", "url": "https://t.co/cGCgRnNTtp", "public_metrics": {"followers_count": 569, "following_count": 746, "tweet_count": 2528, "listed_count": 4}}, {"location": "Boston, Massachusetts", "profile_image_url": "https://pbs.twimg.com/profile_images/1467838713690525706/8PrRis4h_normal.jpg", "created_at": "2009-04-05T23:26:03.000Z", "pinned_tweet_id": "1470414586776072194", "verified": true, "username": "JahHills", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/m6CCXce0pr", "expanded_url": "https://linktr.ee/ryanhwalsh", "display_url": "linktr.ee/ryanhwalsh"}]}, "description": {"mentions": [{"start": 72, "end": 85, "username": "penguinpress"}]}}, "name": "Ryan H. Walsh", "protected": false, "description": "Writer/Musician \u2738 Hallelujah The Hills (the band) \u2738 Astral Weeks (2018 @penguinpress) \u2738 I'll tell you the whole story as soon as we sit down.", "id": "29092660", "url": "https://t.co/m6CCXce0pr", "public_metrics": {"followers_count": 5772, "following_count": 2554, "tweet_count": 62921, "listed_count": 135}}, {"profile_image_url": "https://pbs.twimg.com/profile_images/378800000318879657/b61db9b1fc6981d676a363d6cf0b2318_normal.jpeg", "created_at": "2013-08-18T16:10:36.000Z", "verified": false, "username": "slentine2010", "name": "Scott Lentine", "protected": false, "description": "Autism self-advocate. Poet. I love dogs, traveling, advocating for autism, playing the piano, making new friends, and the beach.", "id": "1681097215", "url": "", "public_metrics": {"followers_count": 510, "following_count": 4081, "tweet_count": 7250, "listed_count": 3}}, {"location": "Baltimore, MD", "profile_image_url": "https://pbs.twimg.com/profile_images/666258588776591360/CbjPccui_normal.jpg", "created_at": "2009-04-08T14:50:18.000Z", "verified": true, "username": "JHUPress", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/HmAC3AEXHK", "expanded_url": "http://www.press.jhu.edu/", "display_url": "press.jhu.edu"}]}, "description": {"mentions": [{"start": 135, "end": 147, "username": "ProjectMUSE"}]}}, "name": "Johns Hopkins University Press", "protected": false, "description": "Publishing cutting edge books and journals since 1878. We envision a future where knowledge enriches the life of every person. Home to @ProjectMUSE.", "id": "29731124", "url": "https://t.co/HmAC3AEXHK", "public_metrics": {"followers_count": 21464, "following_count": 1679, "tweet_count": 19287, "listed_count": 657}}, {"location": "Tucson, AZ", "profile_image_url": "https://pbs.twimg.com/profile_images/969262678043631616/pSwjVKeh_normal.jpg", "created_at": "2016-10-21T21:06:13.000Z", "verified": false, "username": "Ariz_Quarterly", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/o4sshEKfRT", "expanded_url": "https://azq.arizona.edu", "display_url": "azq.arizona.edu"}]}}, "name": "Arizona Quarterly", "protected": false, "description": "Publishing cultural, formal, & theoretical interventions in current academic conversations around American lit, broadly defined.", "id": "789573528458670080", "url": "https://t.co/o4sshEKfRT", "public_metrics": {"followers_count": 357, "following_count": 1080, "tweet_count": 519, "listed_count": 5}}, {"location": "Roma", "profile_image_url": "https://pbs.twimg.com/profile_images/1338569526871543811/metxtMMn_normal.jpg", "created_at": "2020-10-01T19:52:03.000Z", "pinned_tweet_id": "1412324780783636486", "verified": true, "username": "AndreaVenanzoni", "entities": {"url": {"urls": [{"start": 0, "end": 23, "url": "https://t.co/Ack6c8IoCd", "expanded_url": "http://www.forumnazionaleprofessioni.it", "display_url": "forumnazionaleprofessioni.it"}]}, "description": {"mentions": [{"start": 49, "end": 64, "username": "LDO_Fondazione"}, {"start": 67, "end": 80, "username": "atlanticomag"}, {"start": 82, "end": 94, "username": "ilfoglio_it"}, {"start": 96, "end": 100, "username": "tpi"}]}}, "name": "Andrea Venanzoni", "protected": false, "description": "Paleolibertarian, Centro Studi PRAXIS, scrivo su @LDO_Fondazione , @atlanticomag, @ilfoglio_it, @tpi", "id": "1311755732782657536", "url": "https://t.co/Ack6c8IoCd", "public_metrics": {"followers_count": 5200, "following_count": 1958, "tweet_count": 10805, "listed_count": 22}}], "tweets": [{"entities": {"annotations": [{"start": 37, "end": 43, "probability": 0.8885, "type": "Person", "normalized_text": "Franzen"}], "mentions": [{"start": 0, "end": 14, "username": "jodeszgavilan", "id": "37662244"}]}, "source": "Twitter for iPhone", "conversation_id": "1473587774821437441", "text": "@jodeszgavilan Congrats on coming to Franzen w/o the burden of his other shenanigans hahah.", "created_at": "2021-12-22T09:48:57.000Z", "lang": "en", "in_reply_to_user_id": "37662244", "reply_settings": "everyone", "author_id": "917615998047367168", "id": "1473591381436162052", "possibly_sensitive": false, "referenced_tweets": [{"type": "replied_to", "id": "1473590214342094848"}], "public_metrics": {"retweet_count": 0, "reply_count": 1, "like_count": 0, "quote_count": 0}}, {"entities": {"annotations": [{"start": 0, "end": 19, "probability": 0.8219, "type": "Person", "normalized_text": "david foster wallace"}, {"start": 38, "end": 49, "probability": 0.9263, "type": "Person", "normalized_text": "david foster"}]}, "source": "Twitter Web App", "conversation_id": "1392179447051165696", "text": "david foster wallace's dog was called david foster gromit", "created_at": "2021-05-11T18:07:00.000Z", "lang": "en", "reply_settings": "everyone", "author_id": "966631615", "id": "1392179447051165696", "possibly_sensitive": false, "public_metrics": {"retweet_count": 192, "reply_count": 9, "like_count": 1333, "quote_count": 2}}, {"entities": {"annotations": [{"start": 63, "end": 82, "probability": 0.9907, "type": "Person", "normalized_text": "David Foster Wallace"}, {"start": 88, "end": 103, "probability": 0.8899, "type": "Person", "normalized_text": "\u00d3scar Villasante"}], "mentions": [{"start": 28, "end": 42, "username": "camaraabierta", "id": "52823380"}], "urls": [{"start": 105, "end": 128, "url": "https://t.co/758gXJJsrc", "expanded_url": "https://www.youtube.com/watch?v=U9nkvtV8MMM&t=5s", "display_url": "youtube.com/watch?v=U9nkvt\u2026", "images": [{"url": "https://pbs.twimg.com/news_img/1473269052583915531/y4dzsT2L?format=jpg&name=orig", "width": 1280, "height": 720}, {"url": "https://pbs.twimg.com/news_img/1473269052583915531/y4dzsT2L?format=jpg&name=150x150", "width": 150, "height": 150}], "status": 200, "title": "Peque\u00f1o homenaje a David Foster Wallace", "description": "Dos grupos de jubilados charlando en una playa. El primero de temas muy intelectuales, el segundo de muy banales.", "unwound_url": "https://www.youtube.com/watch?v=U9nkvtV8MMM&t=5s"}]}, "source": "Twitter Web App", "conversation_id": "1473262330859429894", "text": "\u2728Premio al Mejor Documental\u2728@camaraabierta\n\"Peque\u00f1o Homenaje a David Foster Wallace\" de \u00d3scar Villasante\nhttps://t.co/758gXJJsrc", "created_at": "2021-12-21T12:29:26.000Z", "lang": "es", "in_reply_to_user_id": "161988497", "reply_settings": "everyone", "author_id": "161988497", "id": "1473269378565160974", "possibly_sensitive": false, "referenced_tweets": [{"type": "replied_to", "id": "1473268624597168133"}], "public_metrics": {"retweet_count": 1, "reply_count": 0, "like_count": 2, "quote_count": 0}, "context_annotations": [{"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}, {"domain": {"id": "54", "name": "Musician", "description": "A musician in the world, like Adele or Bob Dylan"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}]}, {"source": "Twitter for iPhone", "conversation_id": "1472984031864279045", "attachments": {"media_keys": ["3_1472987836517339136"]}, "entities": {"mentions": [{"start": 0, "end": 10, "username": "jdceulaer", "id": "292945752"}, {"start": 11, "end": 26, "username": "WimOosterlinck", "id": "53060760"}], "urls": [{"start": 49, "end": 72, "url": "https://t.co/pFDY3OjlEU", "expanded_url": "https://twitter.com/TomA3aenssens/status/1472987840288116740/photo/1", "display_url": "pic.twitter.com/pFDY3OjlEU"}]}, "text": "@jdceulaer @WimOosterlinck Ik gok op Bultinck.\n\ud83d\ude05 https://t.co/pFDY3OjlEU", "created_at": "2021-12-20T17:50:42.000Z", "lang": "nl", "in_reply_to_user_id": "292945752", "reply_settings": "everyone", "author_id": "1189576208", "id": "1472987840288116740", "possibly_sensitive": false, "referenced_tweets": [{"type": "replied_to", "id": "1472984904023658502"}], "public_metrics": {"retweet_count": 0, "reply_count": 1, "like_count": 8, "quote_count": 0}, "context_annotations": [{"domain": {"id": "3", "name": "TV Shows", "description": "Television shows from around the world"}, "entity": {"id": "10029436825", "name": "Gok : le\u00e7ons de style"}}]}, {"source": "Twitter Web App", "conversation_id": "1472600656787742725", "entities": {"mentions": [{"start": 0, "end": 16, "username": "TheLastSisyphus", "id": "340072715"}]}, "text": "@TheLastSisyphus I read this one but unfortunately not what I need. I appreciate the link though, brother \ud83d\ude4f", "created_at": "2021-12-19T16:28:08.000Z", "lang": "en", "in_reply_to_user_id": "340072715", "reply_settings": "everyone", "author_id": "1357934563838812161", "id": "1472604673962037250", "possibly_sensitive": false, "referenced_tweets": [{"type": "replied_to", "id": "1472601979729981447"}], "public_metrics": {"retweet_count": 0, "reply_count": 1, "like_count": 1, "quote_count": 0}}, {"entities": {"annotations": [{"start": 114, "end": 130, "probability": 0.9954, "type": "Person", "normalized_text": "Alfredo Rodr\u00edguez"}, {"start": 173, "end": 209, "probability": 0.7925, "type": "Person", "normalized_text": "Kelly M Grandal Ana Teresa Rodr\u00edguez"}, {"start": 214, "end": 218, "probability": 0.5481, "type": "Person", "normalized_text": "Riera"}, {"start": 260, "end": 272, "probability": 0.9384, "type": "Person", "normalized_text": "Truman Capote"}], "mentions": [{"start": 18, "end": 25, "username": "Unimet", "id": "32280530"}, {"start": 155, "end": 171, "username": "Aglaia_Berlutti", "id": "45840741"}, {"start": 222, "end": 230, "username": "yoyiahu", "id": "62674070"}], "urls": [{"start": 274, "end": 297, "url": "https://t.co/c2y1pSLJCS", "expanded_url": "https://twitter.com/velazquera/status/1471895454103314433/photo/1", "display_url": "pic.twitter.com/c2y1pSLJCS"}]}, "source": "Twitter for Android", "conversation_id": "1471895454103314433", "attachments": {"media_keys": ["3_1471895448835215364"]}, "text": "Nueva publicaci\u00f3n @Unimet en f\u00edsico con ensayos sobre Literatura norteamericana\nGracias a nuestro editor profesor Alfredo Rodr\u00edguez y a la colaboraci\u00f3n de @Aglaia_Berlutti Kelly M Grandal Ana Teresa Rodr\u00edguez de Riera y @yoyiahu \nEl m\u00edo es sobre el terrible Truman Capote https://t.co/c2y1pSLJCS", "created_at": "2021-12-17T17:29:57.000Z", "lang": "es", "reply_settings": "everyone", "author_id": "796004142007324672", "id": "1471895454103314433", "possibly_sensitive": false, "public_metrics": {"retweet_count": 10, "reply_count": 3, "like_count": 31, "quote_count": 1}, "context_annotations": [{"domain": {"id": "65", "name": "Interests and Hobbies Vertical", "description": "Top level interests and hobbies groupings, like Food or Travel"}, "entity": {"id": "1280550787207147521", "name": "Arts & culture"}}]}, {"entities": {"annotations": [{"start": 31, "end": 50, "probability": 0.9629, "type": "Person", "normalized_text": "Paul Thomas Anderson"}, {"start": 65, "end": 68, "probability": 0.962, "type": "Person", "normalized_text": "Lynn"}, {"start": 77, "end": 90, "probability": 0.9166, "type": "Person", "normalized_text": "Ernie Anderson"}, {"start": 117, "end": 119, "probability": 0.8978, "type": "Organization", "normalized_text": "ABC"}, {"start": 122, "end": 130, "probability": 0.4358, "type": "Person", "normalized_text": "Ghoulardi"}, {"start": 135, "end": 143, "probability": 0.8304, "type": "Place", "normalized_text": "Cleveland"}, {"start": 178, "end": 181, "probability": 0.6344, "type": "Organization", "normalized_text": "WCVB"}], "mentions": [{"start": 0, "end": 9, "username": "JahHills", "id": "29092660"}]}, "source": "Twitter Web App", "conversation_id": "1471842268072095754", "text": "@JahHills I love the fact that Paul Thomas Anderson\u2019s father was Lynn native Ernie Anderson, the promo announcer for ABC, Ghoulardi in Cleveland and an announcer for the news on WCVB 5.", "created_at": "2021-12-17T13:58:36.000Z", "lang": "en", "in_reply_to_user_id": "29092660", "reply_settings": "everyone", "author_id": "1681097215", "id": "1471842268072095754", "possibly_sensitive": false, "public_metrics": {"retweet_count": 0, "reply_count": 1, "like_count": 2, "quote_count": 0}, "context_annotations": [{"domain": {"id": "45", "name": "Brand Vertical", "description": "Top level entities that describe a Brands industry"}, "entity": {"id": "781974597310615553", "name": "Entertainment"}}, {"domain": {"id": "46", "name": "Brand Category", "description": "Categories within Brand Verticals that narrow down the scope of Brands"}, "entity": {"id": "781974596157181956", "name": "Online Site"}}, {"domain": {"id": "46", "name": "Brand Category", "description": "Categories within Brand Verticals that narrow down the scope of Brands"}, "entity": {"id": "781974597105094656", "name": "TV/Movies Related"}}, {"domain": {"id": "47", "name": "Brand", "description": "Brands and Companies"}, "entity": {"id": "1065650820518051840", "name": "ABC News", "description": "ABC News"}}]}], "media": [{"type": "photo", "alt_text": "A close-up of a tennis ball resting on a tennis court in front of a net. ", "height": 442, "width": 789, "url": "https://pbs.twimg.com/media/FG0W1yhWYAI-B0D.jpg", "media_key": "3_1471857766570549250"}]}, "meta": {"newest_id": "1473826748169175048", "oldest_id": "1471808169630392327", "result_count": 13}, "__twarc": {"url": "https://api.twitter.com/2/tweets/search/recent?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ctext%2Cpossibly_sensitive%2Creferenced_tweets%2Creply_settings%2Csource%2Cwithheld&user.fields=created_at%2Cdescription%2Centities%2Cid%2Clocation%2Cname%2Cpinned_tweet_id%2Cprofile_image_url%2Cprotected%2Cpublic_metrics%2Curl%2Cusername%2Cverified%2Cwithheld&media.fields=alt_text%2Cduration_ms%2Cheight%2Cmedia_key%2Cpreview_image_url%2Ctype%2Curl%2Cwidth%2Cpublic_metrics&poll.fields=duration_minutes%2Cend_datetime%2Cid%2Coptions%2Cvoting_status&place.fields=contained_within%2Ccountry%2Ccountry_code%2Cfull_name%2Cgeo%2Cid%2Cname%2Cplace_type&query=David+Foster+Wallace+is%3Averified&max_results=100", "version": "2.8.2", "retrieved_at": "2021-12-23T14:36:34+00:00"}}
melaniewalsh/Intro-Cultural-AnalyticsThe tweets and tweet metadata above are being printed to the notebook. But we want to save this information to a file so we can work with it.
To output Twitter data to a file, we can also include a filename with the “.jsonl” file extension, which stands for JSON lines, a special kind of JSON file.
!twarc2 search "David Foster Wallace is:verified" twitter-data/dfw_last_week.jsonl
100%|██████████████████| Processed 6 days/6 days [00:00<00:00, 13 tweets total ]
Theoretically, a tweet with “David,” “Foster”, and “Wallace” in different places would be matched by the more general search above. If we wanted to match the words “David Foster Wallace” exactly, we would need to put “David Foster Wallace” in quotation marks and “escape” those quotation marks, so that twarc2 will know that our query shouldn’t end at the next quotation mark.
!twarc2 search "\"David Foster Wallace\" is:verified" twitter-data/dfw_exact.jsonl
100%|██████████████████| Processed 6 days/6 days [00:00<00:00, 13 tweets total ]
If you’re working on a Mac, you should be able to escape the quotation marks with backslashes \ before the characters, as shown in the example above. But if you’re working on a Windows computer, you may need to use triple quotations instead, for example:
twarc2 search """ "David Foster Wallace" is:verified""" twitter-data/dfw_exact.jsonl
Get Tweets (Academic Track, Full Twitter Archive)#
Attention
Remember that this functionality is only available to those who have an [Academic Research account](https://developer.twitter.com/en/products/twitter-api/academic-research).To collect tweets from Twitter’s entire historical archive, we need to add the --archive flag.
!twarc2 search "David Foster Wallace bro is:verified" --archive twitter-data/dfw_bro.jsonl
100%|██████████████| Processed 15 years/15 years [00:01<00:00, 30 tweets total ]
Convert JSONL to CSV#
To make our Twitter data easier to work with, we can convert our JSONL file to a CSV file with the twarc-csv plugin, which needs to be installed separately.
!pip install twarc-csv
Once installed, we can use the plug-in from twarc2 with the input filename for the JSONL and a desired output filename for the CSV file.
!twarc2 csv twitter-data/dfw_bro.jsonl twitter-data/dfw_bro.csv
100%|██████████████| Processed 83.7k/83.7k of input file [00:00<00:00, 2.51MB/s]
ℹ️
Parsed 30 tweets objects from 1 lines in the input file.
Wrote 30 rows and output 74 columns in the CSV.
By default, when converting from the JSONL file, twarc-csv will only include tweets that were directly returned from the search.
If you want you can also use --inline-referenced-tweets option to make “referenced” tweets into their own rows in the CSV file. For example, if a quote tweet matched our query, the tweet being quoted would also be included in the CSV file as its own row, even if it didn’t match our query. But as of v0.5.0 of twarc-csv this is no longer the default behavior.
Read in CSV#
Now we’re ready to explore the data!
To work with our tweet data, we can read in our CSV file with pandas and again parse the date column.
tweets_df = pd.read_csv('twitter-data/dfw_bro.csv',
parse_dates = ['created_at'])
If we scroll through this dataset, we can see that there are only 29 tweets that matched our search query, but there is a lot of metadata associated with each tweet. Scroll to the right to see all the information. What category surprises you the most? (For me, it’s the tweet author’s pinned tweet from their own timeline. Your pinned tweet gets attached to everything else you tweet!)
tweets_df
| id | conversation_id | referenced_tweets.replied_to.id | referenced_tweets.retweeted.id | referenced_tweets.quoted.id | author_id | in_reply_to_user_id | retweeted_user_id | quoted_user_id | created_at | text | lang | source | public_metrics.like_count | public_metrics.quote_count | public_metrics.reply_count | public_metrics.retweet_count | reply_settings | possibly_sensitive | withheld.scope | withheld.copyright | withheld.country_codes | entities.annotations | entities.cashtags | entities.hashtags | entities.mentions | entities.urls | context_annotations | attachments.media | attachments.media_keys | attachments.poll.duration_minutes | attachments.poll.end_datetime | attachments.poll.id | attachments.poll.options | attachments.poll.voting_status | attachments.poll_ids | author.id | author.created_at | author.username | author.name | author.description | author.entities.description.cashtags | author.entities.description.hashtags | author.entities.description.mentions | author.entities.description.urls | author.entities.url.urls | author.location | author.pinned_tweet_id | author.profile_image_url | author.protected | author.public_metrics.followers_count | author.public_metrics.following_count | author.public_metrics.listed_count | author.public_metrics.tweet_count | author.url | author.verified | author.withheld.scope | author.withheld.copyright | author.withheld.country_codes | geo.coordinates.coordinates | geo.coordinates.type | geo.country | geo.country_code | geo.full_name | geo.geo.bbox | geo.geo.type | geo.id | geo.name | geo.place_id | geo.place_type | __twarc.retrieved_at | __twarc.url | __twarc.version | Unnamed: 73 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1465671187497840642 | 1465671183370637315 | 1.465671e+18 | NaN | NaN | 78173848 | 78173848.0 | NaN | NaN | 2021-11-30 13:16:56+00:00 | It has little to do with the gender of the author, protagonist, etc. Olga Tokarczuk is just as appealing to male readers as David Foster Wallace (who is considered 'bro lit'). It seems to be more directly related, interestingly enough, to the postmodernist divide in literature. | en | Twitter Web App | 0 | 0 | 1 | 0 | everyone | False | NaN | NaN | NaN | [{"start": 69, "end": 82, "probability": 0.9898, "type": "Person", "normalized_text": "Olga Tokarczuk"}, {"start": 124, "end": 143, "probability": 0.9596, "type": "Person", "normalized_text": "David Foster Wallace"}] | NaN | NaN | NaN | NaN | [{"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "1070731935612198912", "name": "David Foster", "description": "Canadian musician, record producer, songwriter"}}, {"domain": {"id": "54", "name": "Musician", "description": "A musician in the world, like Adele or Bob Dylan"}, "entity": {"id": "1070731935612198912", "name... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 78173848 | 2009-09-29T00:58:33.000Z | TJCarpenterShow | Terry Wayne Carpenter, Jr. | Writer; shitposting. | NaN | NaN | NaN | NaN | NaN | Denver, CO | 1.263100e+18 | https://pbs.twimg.com/profile_images/1360259928091283457/REH2l3d-_normal.jpg | False | 7493 | 170 | 205 | 104059 | NaN | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 1 | 1412360883582418945 | 1412043478301880331 | 1.412361e+18 | NaN | NaN | 342644076 | 82979289.0 | NaN | NaN | 2021-07-06 10:40:49+00:00 | @TomKealy2 @aveek18 @maybeavalon Imo the great twitter literature injustice is that it is david foster wallace and not him that is smeared as the dumb bro contemporary author | en | Twitter Web App | 2 | 0 | 2 | 0 | everyone | False | NaN | NaN | NaN | [{"start": 90, "end": 109, "probability": 0.89, "type": "Person", "normalized_text": "david foster wallace"}] | NaN | NaN | [{"start": 0, "end": 10, "username": "TomKealy2", "id": "82979289", "created_at": "2009-10-16T21:36:07.000Z", "description": "Digital Writer.", "public_metrics": {"followers_count": 1519, "following_count": 1291, "tweet_count": 65190, "listed_count": 25}, "protected": false, "location": "Berlin, Germany", "name": "TomKealy 1\ufe0f\u20e34\ufe0f\u20e39\ufe0f\u20e3\ud83d\udea2", "verified": false... | NaN | [{"domain": {"id": "46", "name": "Brand Category", "description": "Categories within Brand Verticals that narrow down the scope of Brands"}, "entity": {"id": "781974596752842752", "name": "Services"}}, {"domain": {"id": "47", "name": "Brand", "description": "Brands and Companies"}, "entity": {"id": "10045225402", "name": "Twitter"}}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 342644076 | 2011-07-26T10:41:54.000Z | JeyyLowe | Josh Lowe | Policy-focused content guy. (Mostly) ex-journalist. Mediating between evidence and action at global data institute for child safety @EdinburghUni. Views mine. | NaN | NaN | [{"start": 132, "end": 145, "username": "EdinburghUni"}] | NaN | [{"start": 0, "end": 23, "url": "https://t.co/HAkzf1bnPR", "expanded_url": "https://www.ed.ac.uk/impact/research/digital-life/making-data-count-against-child-abuse", "display_url": "ed.ac.uk/impact/researc\u2026"}] | London, England | 1.461288e+18 | https://pbs.twimg.com/profile_images/1441561506634633221/qWUTnkEs_normal.jpg | False | 6190 | 3701 | 129 | 68000 | https://t.co/HAkzf1bnPR | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 2 | 1408833479304003589 | 1408773437431091202 | 1.408819e+18 | NaN | NaN | 15639774 | 4282171.0 | NaN | NaN | 2021-06-26 17:04:10+00:00 | @page88 @IngrahamAngle I heard a tech bro quote a line about cruise ship wait staff from David Foster Wallace's A Supposedly Fun Thing and said it showed how DFW really believed in great customer service. | en | TweetDeck | 11 | 0 | 1 | 0 | everyone | False | NaN | NaN | NaN | [{"start": 89, "end": 108, "probability": 0.9731, "type": "Person", "normalized_text": "David Foster Wallace"}, {"start": 158, "end": 160, "probability": 0.5814, "type": "Place", "normalized_text": "DFW"}] | NaN | NaN | [{"start": 0, "end": 7, "username": "page88", "id": "4282171", "created_at": "2007-04-12T02:18:44.000Z", "description": "Columnist @WIRED & host of THIS IS CRITICAL @Stitcher. Sometimes @latimesopinion, @TheAtlantic, @nytimes. PhD fwiw. Join us at @thiscriticalpod.", "public_metrics": {"followers_count": 150610, "following_count": 4024, "tweet_count": 53115, "listed_count": 2427}, "protected"... | NaN | [{"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "1053753085489606656", "name": "Laura Ingraham", "description": "Laura Ingraham"}}, {"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "1070711281076715520", "name": "Virginia Heffernan", "descripti... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 15639774 | 2008-07-29T00:34:43.000Z | adamdavidson | Adam Davidson | Sharing the lessons I’ve learned from @ThisAmerLife @NewYorker and my baby, @planetmoney on how to make storytelling your superpower at https://t.co/QyMS00u10R | NaN | NaN | [{"start": 38, "end": 51, "username": "ThisAmerLife"}, {"start": 52, "end": 62, "username": "NewYorker"}, {"start": 76, "end": 88, "username": "planetmoney"}] | [{"start": 136, "end": 159, "url": "https://t.co/QyMS00u10R", "expanded_url": "http://www.masterfulstory.com", "display_url": "masterfulstory.com"}] | [{"start": 0, "end": 23, "url": "https://t.co/P16tJd6SDa", "expanded_url": "https://www.masterfulstory.com/", "display_url": "masterfulstory.com"}] | Charlotte, VT | 1.462433e+18 | https://pbs.twimg.com/profile_images/793622420364165120/em1s6fZT_normal.jpg | False | 118449 | 2267 | 2137 | 9323 | https://t.co/P16tJd6SDa | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 3 | 1313590839977947136 | 1313590839977947136 | NaN | 1.313523e+18 | NaN | 602060212 | NaN | 602060212.0 | NaN | 2020-10-06 21:23:56+00:00 | the guy who publicly makes a display of how much feminist literature he reads and waxes on how important bookshelf representation is at least 50% more likely to be a sexpest than the bro who just likes to vibe about david foster wallace and hemingway. this is science. https://t.co/QsvsVxBY15 | en | Twitter Web App | 98 | 1 | 2 | 12 | everyone | False | NaN | NaN | NaN | [{"start": 216, "end": 235, "probability": 0.9361, "type": "Person", "normalized_text": "david foster wallace"}, {"start": 241, "end": 249, "probability": 0.6625, "type": "Person", "normalized_text": "hemingway"}] | NaN | NaN | NaN | [{"start": 269, "end": 292, "url": "https://t.co/QsvsVxBY15", "expanded_url": "https://twitter.com/ebruenig/status/1313522459899985922", "display_url": "twitter.com/ebruenig/statu\u2026"}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 602060212 | 2012-06-07T17:38:18.000Z | ben_geier | Goy Division/Jew Order | Journalist, writer, Brooklyn trash. We’re all hypocrites, but you’re a patriot. Married to my wife, dad to a baby. | NaN | NaN | NaN | NaN | NaN | Brooklyn, NY | 7.233185e+17 | https://pbs.twimg.com/profile_images/1182430150920691712/Yt8LKrXl_normal.jpg | False | 12596 | 2981 | 128 | 47822 | NaN | False | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 4 | 1313523086424186881 | 1313523086424186881 | NaN | NaN | NaN | 602060212 | NaN | NaN | NaN | 2020-10-06 16:54:42+00:00 | the guy who publicly makes a display of how much feminist literature he reads and waxes on how important bookshelf representation is at least 50% more likely to be a sexpest than the bro who just likes to vibe about david foster wallace and hemingway. this is science. https://t.co/QsvsVxBY15 | en | Twitter Web App | 98 | 1 | 2 | 12 | everyone | False | NaN | NaN | NaN | [{"start": 216, "end": 235, "probability": 0.9361, "type": "Person", "normalized_text": "david foster wallace"}, {"start": 241, "end": 249, "probability": 0.6625, "type": "Person", "normalized_text": "hemingway"}] | NaN | NaN | NaN | [{"start": 269, "end": 292, "url": "https://t.co/QsvsVxBY15", "expanded_url": "https://twitter.com/ebruenig/status/1313522459899985922", "display_url": "twitter.com/ebruenig/statu\u2026"}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 602060212 | 2012-06-07T17:38:18.000Z | ben_geier | Goy Division/Jew Order | Journalist, writer, Brooklyn trash. We’re all hypocrites, but you’re a patriot. Married to my wife, dad to a baby. | NaN | NaN | NaN | NaN | NaN | Brooklyn, NY | 7.233185e+17 | https://pbs.twimg.com/profile_images/1182430150920691712/Yt8LKrXl_normal.jpg | False | 12596 | 2981 | 128 | 47822 | NaN | False | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 5 | 1298060678432010240 | 1298060678432010240 | NaN | 1.297936e+18 | NaN | 23314192 | NaN | 236999725.0 | NaN | 2020-08-25 00:52:37+00:00 | david foster wallace bro conversation again? i feel like by this point in the discourse i need footnotes! (just a little "insider" dfw humor for ya) | en | Twitter Web App | 407 | 1 | 4 | 23 | everyone | False | NaN | NaN | NaN | [{"start": 0, "end": 19, "probability": 0.7756, "type": "Person", "normalized_text": "david foster wallace"}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 23314192 | 2009-03-08T14:49:07.000Z | chrisdeville | Chris DeVille | Managing Editor, Stereogum // chris at stereogum dot com | NaN | NaN | NaN | NaN | [{"start": 0, "end": 23, "url": "https://t.co/3jEZqP2it0", "expanded_url": "http://www.stereogum.com", "display_url": "stereogum.com"}] | Columbus | 1.438875e+18 | https://pbs.twimg.com/profile_images/378800000054104895/202f3a3d00921313b1da14a88b0733c9_normal.jpeg | False | 14133 | 995 | 271 | 23755 | https://t.co/3jEZqP2it0 | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 6 | 1297973554986639360 | 1297973554986639360 | NaN | 1.297936e+18 | NaN | 386056280 | NaN | 236999725.0 | NaN | 2020-08-24 19:06:25+00:00 | david foster wallace bro conversation again? i feel like by this point in the discourse i need footnotes! (just a little "insider" dfw humor for ya) | en | Twitter for iPhone | 407 | 1 | 4 | 23 | everyone | False | NaN | NaN | NaN | [{"start": 0, "end": 19, "probability": 0.7756, "type": "Person", "normalized_text": "david foster wallace"}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 386056280 | 2011-10-06T16:00:46.000Z | MaraWilson | Mara “Get Rid of the Nazis” Wilson | On Instagram and Cameo more these days. For info or press please contact Heidi@positivejampr.com. Buy my book WHERE AM I NOW? https://t.co/olmpPDMQk3 | NaN | NaN | NaN | [{"start": 126, "end": 149, "url": "https://t.co/olmpPDMQk3", "expanded_url": "http://bit.ly/1UhjbDf", "display_url": "bit.ly/1UhjbDf"}] | [{"start": 0, "end": 23, "url": "https://t.co/56W7HESHy8", "expanded_url": "http://mara.substack.com", "display_url": "mara.substack.com"}] | L.A., mostly | 1.346261e+18 | https://pbs.twimg.com/profile_images/3379635204/9ac0e9d772744fe2fe68e852ada4fb57_normal.jpeg | False | 611442 | 6437 | 2785 | 174115 | https://t.co/56W7HESHy8 | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 7 | 1296466668898717696 | 1296458752657326081 | 1.296459e+18 | NaN | NaN | 365438535 | 365438535.0 | NaN | NaN | 2020-08-20 15:18:35+00:00 | (Gonna out myself as an insufferable millennial bro and say David Foster Wallace—his maximalism expands my sense of what's possible on the page, as does his notorious blend of academic and colloquial prose. I swear the copy of INFINITE JEST on my shelf is not a display piece.) | en | Twitter Web App | 14 | 0 | 1 | 0 | everyone | False | NaN | NaN | NaN | [{"start": 60, "end": 79, "probability": 0.8772, "type": "Person", "normalized_text": "David Foster Wallace"}, {"start": 227, "end": 239, "probability": 0.4009, "type": "Product", "normalized_text": "INFINITE JEST"}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 365438535 | 2011-08-31T12:57:37.000Z | ben_a_goldfarb | Ben Goldfarb | Independent journalist on the #roadecology beat. Author of EAGER, an award-winning book about beaver belief. | NaN | [{"start": 30, "end": 42, "tag": "roadecology"}] | NaN | NaN | [{"start": 0, "end": 23, "url": "https://t.co/nbpqLWoe9a", "expanded_url": "http://bengoldfarb.com/", "display_url": "bengoldfarb.com"}] | Spokane, WA | 1.336347e+18 | https://pbs.twimg.com/profile_images/1339242927663370240/VoFRzC_X_normal.jpg | False | 9242 | 1999 | 262 | 12967 | https://t.co/nbpqLWoe9a | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 8 | 1259920233600479233 | 1259920233600479233 | NaN | NaN | NaN | 460444548 | NaN | NaN | NaN | 2020-05-11 18:56:06+00:00 | This week for the MEL Review of Books, we had @leahrosenz talk to @adriennemiller about IN THE LAND OF MEN, a memoir of the dude snobbery she faced as the literary editor at Esquire while publishing the likes of David Foster Wallace: \nhttps://t.co/26WQYMgakO | en | Twitter Web App | 9 | 0 | 1 | 1 | everyone | False | NaN | NaN | NaN | [{"start": 18, "end": 36, "probability": 0.4401, "type": "Other", "normalized_text": "MEL Review of Books"}, {"start": 174, "end": 180, "probability": 0.9168, "type": "Organization", "normalized_text": "Esquire"}, {"start": 212, "end": 231, "probability": 0.9804, "type": "Person", "normalized_text": "David Foster Wallace"}] | NaN | NaN | [{"start": 46, "end": 57, "username": "leahrosenz", "id": "734174508", "created_at": "2012-08-03T04:40:47.000Z", "description": "writer, reporter, make believe historian \u2022 words in @slate @genmag @eater @lithub @catapult. extremely freckled lady \u2022 rosenzweig dot leah@gmail", "public_metrics": {"followers_count": 514, "following_count": 1234, "tweet_count": 3690, "listed_count": 9... | [{"start": 239, "end": 262, "url": "https://t.co/26WQYMgakO", "expanded_url": "https://melmagazine.com/en-us/story/how-adrienne-miller-made-it-in-the-1990s-heyday-of-the-postmodern-lit-bro", "display_url": "melmagazine.com/en-us/story/ho\u2026"}] | [{"domain": {"id": "85", "name": "Book Genre", "description": "A genre for books, like Fiction"}, "entity": {"id": "859531094730825728", "name": "Biographies and memoirs", "description": "Biographies and memoirs"}}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 460444548 | 2012-01-10T19:27:50.000Z | MilesKlee | Miles Klee | my followers are of the highest quality | NaN | NaN | NaN | NaN | [{"start": 0, "end": 23, "url": "https://t.co/cHBRAqU8ZO", "expanded_url": "https://melmagazine.com/en-us/story/author/miles-klee", "display_url": "melmagazine.com/en-us/story/au\u2026"}] | LA | 1.387991e+18 | https://pbs.twimg.com/profile_images/1446285855790755846/CQJmPbBv_normal.jpg | False | 26531 | 4995 | 212 | 57004 | https://t.co/cHBRAqU8ZO | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 9 | 1109105414849921029 | 1109105414849921029 | NaN | NaN | 1.109073e+18 | 19197226 | NaN | NaN | 19197226.0 | 2019-03-22 14:51:51+00:00 | "The Great White Male is rap's Grand Inquisitor, its idiot questioner, its Alien Other no less than Reds were for McCarthy." -- David Foster Wallace, on his forays into Dorchester & Roxbury's music scenes, 1989\n\n"I know bro, but still-" -- Brendan McGuirk, reflecting on it, 2019 https://t.co/lYJV5bU7yb | en | Twitter Web Client | 1 | 0 | 1 | 0 | everyone | False | NaN | NaN | NaN | [{"start": 100, "end": 103, "probability": 0.8276, "type": "Organization", "normalized_text": "Reds"}, {"start": 114, "end": 121, "probability": 0.8741, "type": "Person", "normalized_text": "McCarthy"}, {"start": 128, "end": 147, "probability": 0.985, "type": "Person", "normalized_text": "David Foster Wallace"}, {"start": 169, "end": 178, "probability": 0.6148, "type": "Place", "normalized_tex... | NaN | NaN | NaN | [{"start": 284, "end": 307, "url": "https://t.co/lYJV5bU7yb", "expanded_url": "https://twitter.com/BMcGfresh/status/1109072669025148929", "display_url": "twitter.com/BMcGfresh/stat\u2026"}] | [{"domain": {"id": "55", "name": "Music Genre", "description": "A category for a musical style, like Pop, Rock, or Rap"}, "entity": {"id": "810937888334487552", "name": "Rap", "description": "Hip-Hop/Rap"}}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 19197226 | 2009-01-19T19:23:24.000Z | BMcGfresh | Brendan McGuirk | checkpoint unlocked | NaN | NaN | NaN | NaN | NaN | “Boston”/ Somerville, Cambride | 1.431119e+18 | https://pbs.twimg.com/profile_images/1187459820825317376/uD2g6H_C_normal.jpg | False | 1268 | 2404 | 32 | 29910 | NaN | False | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 10 | 1075778924280471553 | 1075778924280471553 | NaN | NaN | 1.075615e+18 | 398088661 | NaN | NaN | 138203134.0 | 2018-12-20 15:44:17+00:00 | Is—is Alexandria Ocasio-Cortez a David Foster Wallace bro? https://t.co/OcwGRUdWMV | en | Twitter for iPhone | 54 | 3 | 3 | 4 | everyone | False | NaN | NaN | NaN | [{"start": 6, "end": 22, "probability": 0.9307, "type": "Person", "normalized_text": "Alexandria Ocasio"}, {"start": 24, "end": 29, "probability": 0.5206, "type": "Person", "normalized_text": "Cortez"}, {"start": 33, "end": 52, "probability": 0.8046, "type": "Person", "normalized_text": "David Foster Wallace"}] | NaN | NaN | NaN | [{"start": 59, "end": 82, "url": "https://t.co/OcwGRUdWMV", "expanded_url": "https://twitter.com/AOC/status/1075614808853110785", "display_url": "twitter.com/AOC/status/107\u2026"}] | [{"domain": {"id": "10", "name": "Person", "description": "Named people in the world like Nelson Mandela"}, "entity": {"id": "1011963575089262593", "name": "Alexandria Ocasio-Cortez", "description": "US Representative from New York Alexandria Ocasio-Cortez"}}, {"domain": {"id": "35", "name": "Politician", "description": "Politicians in the world, like Joe Biden"}, "entity": {"id": "10119635750... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 398088661 | 2011-10-25T15:20:25.000Z | MEPFuller | Matt Fuller | Politics stuff at The Daily Beast. Take these tweets seriously but not literally. | NaN | NaN | NaN | NaN | NaN | Washington, D.C. | NaN | https://pbs.twimg.com/profile_images/1372212210521542658/g83KiBSY_normal.jpg | False | 243473 | 4243 | 3471 | 68255 | NaN | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 11 | 995487617549512704 | 995487617549512704 | NaN | NaN | NaN | 1000899020 | NaN | NaN | NaN | 2018-05-13 02:15:17+00:00 | I got kicked out of KGB Bar in the LES for arguing with a lit bro that David Foster Wallace is a better writer than Thomas Pynchon. https://t.co/iQLxduLtEN | en | Twitter for iPhone | 43 | 0 | 12 | 0 | everyone | False | NaN | NaN | NaN | [{"start": 20, "end": 26, "probability": 0.6016, "type": "Organization", "normalized_text": "KGB Bar"}, {"start": 71, "end": 90, "probability": 0.9265, "type": "Person", "normalized_text": "David Foster Wallace"}, {"start": 116, "end": 129, "probability": 0.9987, "type": "Person", "normalized_text": "Thomas Pynchon"}] | NaN | NaN | NaN | [{"start": 132, "end": 155, "url": "https://t.co/iQLxduLtEN", "expanded_url": "https://twitter.com/bkerogers/status/994737256211648512", "display_url": "twitter.com/bkerogers/stat\u2026"}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 1000899020 | 2012-12-10T04:28:43.000Z | nandelabra | Nandini B. | writer | copy editor | bylines: Wired, Defector, TX Observer, Pacific Standard, Slate, The Week, Ebert Voices, Lit Hub, TNR, Harper’s et al. | she/her | | NaN | NaN | NaN | NaN | [{"start": 0, "end": 23, "url": "https://t.co/roZvHNAj4r", "expanded_url": "https://www.harpersbazaar.com/culture/film-tv/a38539663/amrit-kaur-sex-lives-of-college-girls-interview/", "display_url": "harpersbazaar.com/culture/film-t\u2026"}] | Texas | 5.968889e+17 | https://pbs.twimg.com/profile_images/1300802944443576322/rq62G8QT_normal.jpg | False | 7506 | 1018 | 107 | 310196 | https://t.co/roZvHNAj4r | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 12 | 898246334804787202 | 898246334804787202 | NaN | 8.982432e+17 | NaN | 19608605 | NaN | 275829938.0 | NaN | 2017-08-17 18:13:09+00:00 | UPDATE: I met a "Have you read David Foster Wallace?" bro at law school. It only took four days, fam. FOUR. | en | TweetDeck | 12 | 0 | 2 | 1 | everyone | False | NaN | NaN | NaN | [{"start": 31, "end": 50, "probability": 0.9482, "type": "Person", "normalized_text": "David Foster Wallace"}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 19608605 | 2009-01-27T19:01:11.000Z | thesarahkelly | sarah | Editor, mostly copy, @sinow. Diversity fellow, @APSE_sportmedia. Previously: @WaPoExpress, @SBNation, @theeagle. Lawrence native, KU grad. Trajan sucks. | NaN | NaN | [{"start": 21, "end": 27, "username": "sinow"}, {"start": 47, "end": 63, "username": "APSE_sportmedia"}, {"start": 77, "end": 89, "username": "WaPoExpress"}, {"start": 91, "end": 100, "username": "SBNation"}, {"start": 102, "end": 111, "username": "theeagle"}] | NaN | [{"start": 0, "end": 23, "url": "https://t.co/mJv97A4ukN", "expanded_url": "http://pubtbnl.com", "display_url": "pubtbnl.com"}] | District of Columbia | NaN | https://pbs.twimg.com/profile_images/1432685329262202880/GVsXHJpr_normal.jpg | False | 12456 | 3037 | 172 | 268232 | https://t.co/mJv97A4ukN | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 13 | 844552567522820096 | 844552567522820096 | NaN | NaN | NaN | 15649438 | NaN | NaN | NaN | 2017-03-22 14:13:17+00:00 | "David Foster Wallace is essentially the same as skiing and cigars now.” https://t.co/GPCbgdBL3e | en | TweetDeck | 14 | 3 | 2 | 4 | everyone | False | NaN | NaN | NaN | [{"start": 1, "end": 20, "probability": 0.9252, "type": "Person", "normalized_text": "David Foster Wallace"}] | NaN | NaN | NaN | [{"start": 73, "end": 96, "url": "https://t.co/GPCbgdBL3e", "expanded_url": "https://newrepublic.com/minutes/141498/neil-gorsuch-will-first-lit-bro-supreme-court-justice", "display_url": "newrepublic.com/minutes/141498\u2026", "status": 200, "unwound_url": "https://newrepublic.com/minutes/141498/neil-gorsuch-will-first-lit-bro-supreme-court-justice"}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 15649438 | 2008-07-29T18:39:26.000Z | theferocity | Saeed Jones | I’m chaotic and always right. ✨Forthcoming: ALIVE AT THE END OF THE WORLD, Fall 2022. ✨Previously: HOW WE FIGHT FOR OUR LIVES. Reps: @TuesdayAgency @SheedyLit. | NaN | NaN | [{"start": 133, "end": 147, "username": "TuesdayAgency"}, {"start": 148, "end": 158, "username": "SheedyLit"}] | NaN | [{"start": 0, "end": 23, "url": "https://t.co/ZxMTYThmyn", "expanded_url": "http://saeedjones.substack.com", "display_url": "saeedjones.substack.com"}] | Columbus, OH | 1.460278e+18 | https://pbs.twimg.com/profile_images/1463168071703707655/b2OybFGc_normal.jpg | False | 220907 | 939 | 1738 | 227013 | https://t.co/ZxMTYThmyn | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 14 | 760889024403873792 | 760889024403873792 | NaN | NaN | NaN | 193477066 | NaN | NaN | NaN | 2016-08-03 17:24:14+00:00 | New theory: Bernie Bro holdouts are exactly the same people as David Foster Wallace fanatics. Yes? | en | Twitter Web Client | 14 | 0 | 2 | 0 | everyone | False | NaN | NaN | NaN | [{"start": 12, "end": 17, "probability": 0.8566, "type": "Person", "normalized_text": "Bernie"}, {"start": 63, "end": 82, "probability": 0.958, "type": "Person", "normalized_text": "David Foster Wallace"}] | NaN | NaN | NaN | NaN | [{"domain": {"id": "35", "name": "Politician", "description": "Politicians in the world, like Joe Biden"}, "entity": {"id": "10037721459", "name": "Bernie Sanders", "description": "US Senator Bernie Sanders (VT)\n"}}, {"domain": {"id": "38", "name": "Political Race", "description": ""}, "entity": {"id": "10037066629", "name": "2016 US Elections", "description": "2016 US Elections"}}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 193477066 | 2010-09-21T22:36:55.000Z | rebeccamakkai | Rebecca Makkai | Pulitzer & Nat'l Book Award finalist, winner of ALA Carnegie Medal for THE GREAT BELIEVERS. Artistic Director at @storystudio. She/her. Daughter of a refugee. | NaN | NaN | [{"start": 113, "end": 125, "username": "storystudio"}] | NaN | [{"start": 0, "end": 23, "url": "https://t.co/KuRhUDS3Ej", "expanded_url": "http://www.rebeccamakkai.com", "display_url": "rebeccamakkai.com"}] | Chicago | 1.466140e+18 | https://pbs.twimg.com/profile_images/1200639503112769536/4E9lQ4o6_normal.jpg | False | 37361 | 3104 | 421 | 25587 | https://t.co/KuRhUDS3Ej | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 15 | 733665498148294657 | 733665146216779776 | 7.336651e+17 | NaN | NaN | 398088661 | 398088661.0 | NaN | NaN | 2016-05-20 14:27:40+00:00 | Am I a David Foster Wallace bro? Very well, I'm a David Foster Wallace bro. | en | Twitter for iPhone | 2 | 0 | 1 | 1 | everyone | False | NaN | NaN | NaN | [{"start": 7, "end": 26, "probability": 0.9195, "type": "Person", "normalized_text": "David Foster Wallace"}, {"start": 50, "end": 69, "probability": 0.9235, "type": "Person", "normalized_text": "David Foster Wallace"}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 398088661 | 2011-10-25T15:20:25.000Z | MEPFuller | Matt Fuller | Politics stuff at The Daily Beast. Take these tweets seriously but not literally. | NaN | NaN | NaN | NaN | NaN | Washington, D.C. | NaN | https://pbs.twimg.com/profile_images/1372212210521542658/g83KiBSY_normal.jpg | False | 243473 | 4243 | 3471 | 68255 | NaN | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 16 | 694224894805032964 | 694224894805032964 | NaN | NaN | NaN | 605556917 | NaN | NaN | NaN | 2016-02-01 18:24:47+00:00 | David Foster Wallace sucks and this is a great review of interminable jest, via @Bro_Pair https://t.co/hxGFGY6D3Z | en | TweetDeck | 6 | 0 | 0 | 0 | everyone | False | NaN | NaN | NaN | [{"start": 0, "end": 19, "probability": 0.9365, "type": "Person", "normalized_text": "David Foster Wallace"}] | NaN | NaN | [{"start": 80, "end": 89, "username": "Bro_Pair", "id": "56309136", "created_at": "2009-07-13T06:45:31.000Z", "description": "\"...All cats are wicked, though often useful. Who has not seen Satan in their sly faces?\"\n\nSUBSCRIBE TO MY @GHOST NEWSLETTER! https://t.co/aBXZ1krlUh", "public_metrics": {"followers_count": 53149, "following_count": 1889, "tweet_count": 3508, "listed_count": 849}, "... | [{"start": 90, "end": 113, "url": "https://t.co/hxGFGY6D3Z", "expanded_url": "http://www.cosmoetica.com/b326-des266.htm", "display_url": "cosmoetica.com/b326-des266.htm"}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 605556917 | 2012-06-11T16:37:29.000Z | deep_beige | Brendan james | Co-host and producer @Blowbackpod. "The Great Vorelli" \nbjames0928@gmail.com | NaN | NaN | [{"start": 21, "end": 33, "username": "Blowbackpod"}] | NaN | [{"start": 0, "end": 23, "url": "https://t.co/43nJI3NwmR", "expanded_url": "https://open.spotify.com/artist/6T2Z3aTfHhGUSVV98su64B?si=65t1FbjRSzmpQDSIgJm5Vw&dl_branch=1", "display_url": "open.spotify.com/artist/6T2Z3aT\u2026"}] | Joe Don Baker Museum | 1.410032e+18 | https://pbs.twimg.com/profile_images/1453502026797752328/B8uZ1NsJ_normal.jpg | False | 73139 | 2382 | 635 | 52048 | https://t.co/43nJI3NwmR | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 17 | 686753187727044609 | 686753187727044609 | NaN | NaN | NaN | 56993835 | NaN | NaN | NaN | 2016-01-12 03:34:53+00:00 | "Bro stop being such a David Foster Wallace footnote" | en | Twitter for iPhone | 2 | 0 | 1 | 0 | everyone | False | NaN | NaN | NaN | [{"start": 23, "end": 42, "probability": 0.9363, "type": "Person", "normalized_text": "David Foster Wallace"}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 56993835 | 2009-07-15T11:42:30.000Z | Dooezer | Mary Dooe | podcast creator. MBA. quite contrary. founder of Dooe Diligence Media. past work @marketplace @wbur @nprwest @wgbh @harvardbiz @iheartradio. https://t.co/514RH9nvyk | NaN | NaN | [{"start": 81, "end": 93, "username": "marketplace"}, {"start": 94, "end": 99, "username": "wbur"}, {"start": 100, "end": 108, "username": "nprwest"}, {"start": 109, "end": 114, "username": "wgbh"}, {"start": 115, "end": 126, "username": "harvardbiz"}, {"start": 127, "end": 139, "username": "iheartradio"}] | [{"start": 141, "end": 164, "url": "https://t.co/514RH9nvyk", "expanded_url": "http://marydooe.com", "display_url": "marydooe.com"}] | NaN | East Coast | 6.135466e+17 | https://pbs.twimg.com/profile_images/1335449532084137986/SbMbv2ZT_normal.jpg | False | 4394 | 1079 | 147 | 46178 | NaN | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 18 | 644308060937265152 | 644308060937265152 | NaN | 6.443079e+17 | NaN | 61734492 | NaN | 398088661.0 | NaN | 2015-09-17 00:33:07+00:00 | Did Carly Fiorina just make a David Foster Wallace reference?\n\nIs Carly Fiorina a David Foster Wallace bro?? | en | Twitter Web Client | 12 | 0 | 0 | 5 | everyone | False | NaN | NaN | NaN | [{"start": 4, "end": 16, "probability": 0.9955, "type": "Person", "normalized_text": "Carly Fiorina"}, {"start": 30, "end": 49, "probability": 0.9285, "type": "Person", "normalized_text": "David Foster Wallace"}, {"start": 66, "end": 78, "probability": 0.9941, "type": "Person", "normalized_text": "Carly Fiorina"}, {"start": 82, "end": 101, "probability": 0.9103, "type": "Person", "normalized_t... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 61734492 | 2009-07-31T09:29:37.000Z | Fahrenthold | David Fahrenthold | Washington Post reporter, covering former President Trump's businesses. MSNBC contributor. If you don't want it printed, don't let it happen. | NaN | NaN | NaN | NaN | [{"start": 0, "end": 23, "url": "https://t.co/fJMCeIYylK", "expanded_url": "http://www.washingtonpost.com", "display_url": "washingtonpost.com"}] | Washington, DC | NaN | https://pbs.twimg.com/profile_images/1021824606087331841/_gPQBRax_normal.jpg | False | 837670 | 5583 | 9482 | 52817 | https://t.co/fJMCeIYylK | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 19 | 644307992901517312 | 644307992901517312 | NaN | 6.443079e+17 | NaN | 22330423 | NaN | 398088661.0 | NaN | 2015-09-17 00:32:50+00:00 | Did Carly Fiorina just make a David Foster Wallace reference?\n\nIs Carly Fiorina a David Foster Wallace bro?? | en | Twitter for iPhone | 12 | 0 | 0 | 5 | everyone | False | NaN | NaN | NaN | [{"start": 4, "end": 16, "probability": 0.9955, "type": "Person", "normalized_text": "Carly Fiorina"}, {"start": 30, "end": 49, "probability": 0.9285, "type": "Person", "normalized_text": "David Foster Wallace"}, {"start": 66, "end": 78, "probability": 0.9941, "type": "Person", "normalized_text": "Carly Fiorina"}, {"start": 82, "end": 101, "probability": 0.9103, "type": "Person", "normalized_t... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 22330423 | 2009-03-01T04:12:01.000Z | ColinACurtis | Colin Curtis | Dem hack | Alum of campaigns, legislatures, & unions | BBQ enthusiast | Occasional writer | Gamer | Royals & Chiefs fan | Dotte / Kansan turned DC dweller | NaN | NaN | NaN | NaN | [{"start": 0, "end": 23, "url": "https://t.co/q8x9QutSUm", "expanded_url": "https://www.twitch.tv/adg913", "display_url": "twitch.tv/adg913"}] | Washington, DC | NaN | https://pbs.twimg.com/profile_images/1455343198134579201/Fy6TrHJZ_normal.jpg | False | 7506 | 1471 | 223 | 69201 | https://t.co/q8x9QutSUm | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 20 | 644307901830561793 | 644307901830561793 | NaN | NaN | NaN | 398088661 | NaN | NaN | NaN | 2015-09-17 00:32:29+00:00 | Did Carly Fiorina just make a David Foster Wallace reference?\n\nIs Carly Fiorina a David Foster Wallace bro?? | en | Twitter for iPhone | 12 | 0 | 0 | 5 | everyone | False | NaN | NaN | NaN | [{"start": 4, "end": 16, "probability": 0.9955, "type": "Person", "normalized_text": "Carly Fiorina"}, {"start": 30, "end": 49, "probability": 0.9285, "type": "Person", "normalized_text": "David Foster Wallace"}, {"start": 66, "end": 78, "probability": 0.9941, "type": "Person", "normalized_text": "Carly Fiorina"}, {"start": 82, "end": 101, "probability": 0.9103, "type": "Person", "normalized_t... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 398088661 | 2011-10-25T15:20:25.000Z | MEPFuller | Matt Fuller | Politics stuff at The Daily Beast. Take these tweets seriously but not literally. | NaN | NaN | NaN | NaN | NaN | Washington, D.C. | NaN | https://pbs.twimg.com/profile_images/1372212210521542658/g83KiBSY_normal.jpg | False | 243473 | 4243 | 3471 | 68255 | NaN | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 21 | 632152536636608512 | 632152536636608512 | NaN | NaN | NaN | 19816859 | NaN | NaN | NaN | 2015-08-14 11:31:24+00:00 | "David Foster Wallace was not a bro: Let’s not paint the writer with the same brush as his fans" | Salon http://t.co/t4FqgmoyVz | en | Hootsuite | 19 | 0 | 0 | 10 | everyone | False | NaN | NaN | NaN | [{"start": 1, "end": 20, "probability": 0.9133, "type": "Person", "normalized_text": "David Foster Wallace"}] | NaN | NaN | NaN | [{"start": 105, "end": 127, "url": "http://t.co/t4FqgmoyVz", "expanded_url": "http://pwne.ws/1fbCjQB", "display_url": "pwne.ws/1fbCjQB", "status": 200, "unwound_url": "https://www.salon.com/2015/08/13/david_foster_wallace_was_not_a_bro_lets_not_paint_the_writer_with_the_same_brush_as_his_fans/"}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 19816859 | 2009-01-31T14:38:55.000Z | PublishersWkly | Publishers Weekly | The international source for book publishing and bookselling news, reviews, and information. | NaN | NaN | NaN | NaN | [{"start": 0, "end": 23, "url": "https://t.co/cR5ERFihe5", "expanded_url": "http://www.publishersweekly.com/", "display_url": "publishersweekly.com"}] | New York City | NaN | https://pbs.twimg.com/profile_images/472046796202459136/7aCV2gq3_normal.jpeg | False | 806586 | 605 | 11718 | 81057 | https://t.co/cR5ERFihe5 | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 22 | 631931489769390080 | 631931489769390080 | NaN | NaN | NaN | 16955991 | NaN | NaN | NaN | 2015-08-13 20:53:02+00:00 | David Foster Wallace was *not* a bro: Don't paint the writer with the same brush as his fans http://t.co/vZvwEien22 | en | SocialFlow | 16 | 0 | 3 | 10 | everyone | False | NaN | NaN | NaN | [{"start": 0, "end": 19, "probability": 0.9181, "type": "Person", "normalized_text": "David Foster Wallace"}] | NaN | NaN | NaN | [{"start": 93, "end": 115, "url": "http://t.co/vZvwEien22", "expanded_url": "http://slnm.us/QwmAbPX", "display_url": "slnm.us/QwmAbPX"}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 16955991 | 2008-10-24T20:13:31.000Z | Salon | Salon | The original online source for news, politics and entertainment | Find us on Instagram & TikTok: salonofficial | Subscribe to our newsletters linked below | NaN | NaN | NaN | NaN | [{"start": 0, "end": 23, "url": "https://t.co/v7CORYKFyC", "expanded_url": "https://www.salon.com/newsletter", "display_url": "salon.com/newsletter"}] | NaN | 1.471924e+18 | https://pbs.twimg.com/profile_images/793144947444707328/obBB1x2a_normal.jpg | False | 965887 | 5871 | 0 | 238960 | https://t.co/v7CORYKFyC | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 23 | 631828145105162240 | 631828145105162240 | NaN | 6.318255e+17 | NaN | 89805327 | NaN | 19923638.0 | NaN | 2015-08-13 14:02:23+00:00 | You probably know a bro who says he loves David Foster Wallace: http://t.co/3KfOlw2UR6 http://t.co/xNI9tbF02p | en | Twitter for iPhone | 5 | 0 | 0 | 7 | everyone | False | NaN | NaN | NaN | [{"start": 42, "end": 61, "probability": 0.9218, "type": "Person", "normalized_text": "David Foster Wallace"}] | NaN | NaN | NaN | [{"start": 64, "end": 86, "url": "http://t.co/3KfOlw2UR6", "expanded_url": "http://thecut.io/1Plvg4X", "display_url": "thecut.io/1Plvg4X"}, {"start": 87, "end": 109, "url": "http://t.co/xNI9tbF02p", "expanded_url": "https://twitter.com/TheCut/status/631825543202213889/photo/1", "display_url": "pic.twitter.com/xNI9tbF02p"}] | NaN | [{"url": "https://pbs.twimg.com/media/CMSx-8XWcAAnkK-.jpg", "type": "photo", "media_key": "3_631825542652784640", "height": 400, "width": 600}] | ["3_631825542652784640"] | NaN | NaN | NaN | NaN | NaN | NaN | 89805327 | 2009-11-13T22:07:38.000Z | Gwen_UsBeauty | Gwen Flamberg | Beauty, style and lifestyle influencer. Red Carpet beauty and style expert and makeup addict. Tweets are my own. | NaN | NaN | NaN | NaN | [{"start": 0, "end": 23, "url": "https://t.co/Zz45dZzxqJ", "expanded_url": "http://www.usmagazine.com/stylebeauty/beauty-trendwatch", "display_url": "usmagazine.com/stylebeauty/be\u2026"}] | Everywhere it's beautiful | NaN | https://pbs.twimg.com/profile_images/525378071/gwen_normal.jpg | False | 36087 | 2133 | 472 | 71681 | https://t.co/Zz45dZzxqJ | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 24 | 631825643441901568 | 631825643441901568 | NaN | 6.318255e+17 | NaN | 1101966512 | NaN | 19923638.0 | NaN | 2015-08-13 13:52:26+00:00 | You probably know a bro who says he loves David Foster Wallace: http://t.co/3KfOlw2UR6 http://t.co/xNI9tbF02p | en | TweetDeck | 5 | 0 | 0 | 7 | everyone | False | NaN | NaN | NaN | [{"start": 42, "end": 61, "probability": 0.9218, "type": "Person", "normalized_text": "David Foster Wallace"}] | NaN | NaN | NaN | [{"start": 64, "end": 86, "url": "http://t.co/3KfOlw2UR6", "expanded_url": "http://thecut.io/1Plvg4X", "display_url": "thecut.io/1Plvg4X"}, {"start": 87, "end": 109, "url": "http://t.co/xNI9tbF02p", "expanded_url": "https://twitter.com/TheCut/status/631825543202213889/photo/1", "display_url": "pic.twitter.com/xNI9tbF02p"}] | NaN | [{"url": "https://pbs.twimg.com/media/CMSx-8XWcAAnkK-.jpg", "type": "photo", "media_key": "3_631825542652784640", "height": 400, "width": 600}] | ["3_631825542652784640"] | NaN | NaN | NaN | NaN | NaN | NaN | 1101966512 | 2013-01-18T20:40:41.000Z | Blumsteinboy | Ian Harrison | Decolonize it all. 🇬🇾 | NaN | NaN | NaN | NaN | NaN | Tiohtià:ke/Montréal | NaN | https://pbs.twimg.com/profile_images/934550443723771904/3rjskH7W_normal.jpg | False | 1631 | 1388 | 52 | 15962 | NaN | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 25 | 631825543202213889 | 631825543202213889 | NaN | NaN | NaN | 19923638 | NaN | NaN | NaN | 2015-08-13 13:52:02+00:00 | You probably know a bro who says he loves David Foster Wallace: http://t.co/3KfOlw2UR6 http://t.co/xNI9tbF02p | en | SocialFlow | 5 | 0 | 0 | 7 | everyone | False | NaN | NaN | NaN | [{"start": 42, "end": 61, "probability": 0.9218, "type": "Person", "normalized_text": "David Foster Wallace"}] | NaN | NaN | NaN | [{"start": 64, "end": 86, "url": "http://t.co/3KfOlw2UR6", "expanded_url": "http://thecut.io/1Plvg4X", "display_url": "thecut.io/1Plvg4X"}, {"start": 87, "end": 109, "url": "http://t.co/xNI9tbF02p", "expanded_url": "https://twitter.com/TheCut/status/631825543202213889/photo/1", "display_url": "pic.twitter.com/xNI9tbF02p"}] | NaN | [{"url": "https://pbs.twimg.com/media/CMSx-8XWcAAnkK-.jpg", "type": "photo", "media_key": "3_631825542652784640", "height": 400, "width": 600}] | ["3_631825542652784640"] | NaN | NaN | NaN | NaN | NaN | NaN | 19923638 | 2009-02-02T19:13:01.000Z | TheCut | The Cut | Style. Self. Culture. Power.\nFind us on Instagram: @TheCut\nSubscribe to New York for more: https://t.co/1OtjTJftYM | NaN | NaN | [{"start": 51, "end": 58, "username": "TheCut"}] | [{"start": 91, "end": 114, "url": "https://t.co/1OtjTJftYM", "expanded_url": "http://nymag.com/subscribe", "display_url": "nymag.com/subscribe"}] | [{"start": 0, "end": 23, "url": "https://t.co/LXYpRGXBZm", "expanded_url": "https://thecut.com", "display_url": "thecut.com"}] | New York, NY | 1.466436e+18 | https://pbs.twimg.com/profile_images/899259308445020161/OL2Y5xmv_normal.jpg | False | 1425875 | 4307 | 10273 | 219635 | https://t.co/LXYpRGXBZm | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 26 | 631820349290774528 | 631820349290774528 | NaN | 6.318203e+17 | NaN | 24512235 | NaN | 13566872.0 | NaN | 2015-08-13 13:31:24+00:00 | All men are bad but are David Foster Wallace fans a special kind of bad? http://t.co/w5KOvJBcui http://t.co/yBhOr3aPjy | en | TweetDeck | 27 | 0 | 3 | 8 | everyone | False | NaN | NaN | NaN | [{"start": 24, "end": 43, "probability": 0.931, "type": "Person", "normalized_text": "David Foster Wallace"}] | NaN | NaN | NaN | [{"start": 73, "end": 95, "url": "http://t.co/w5KOvJBcui", "expanded_url": "http://www.theawl.com/2015/08/the-bro-of-the-system", "display_url": "theawl.com/2015/08/the-br\u2026"}, {"start": 96, "end": 118, "url": "http://t.co/yBhOr3aPjy", "expanded_url": "https://twitter.com/Awl/status/631820274330136576/photo/1", "display_url": "pic.twitter.com/yBhOr3aPjy"}] | NaN | [{"url": "https://pbs.twimg.com/media/CMStMPvXAAA5a1J.jpg", "type": "photo", "media_key": "3_631820273633918976", "height": 235, "width": 278}] | ["3_631820273633918976"] | NaN | NaN | NaN | NaN | NaN | NaN | 24512235 | 2009-03-15T11:34:04.000Z | sts10 | Sam Schlinkert | Content Programming Editor at @CNNplus. Sometimes programmer. | NaN | NaN | [{"start": 30, "end": 38, "username": "CNNplus"}] | NaN | [{"start": 0, "end": 23, "url": "https://t.co/BJNkskvCIp", "expanded_url": "https://www.samschlinkert.com", "display_url": "samschlinkert.com"}] | New York, NY | NaN | https://pbs.twimg.com/profile_images/698574801842126849/Zm-Vsr3u_normal.png | False | 4118 | 1247 | 145 | 24526 | https://t.co/BJNkskvCIp | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 27 | 545020559248343040 | 545020559248343040 | NaN | NaN | NaN | 415297424 | NaN | NaN | NaN | 2014-12-17 01:00:01+00:00 | My blog bro David (@BDsCocktailHour) reacts to David Foster Wallace's teaching Gessner. With footnotes. #BillandDaves http://t.co/gU84ybdk2C | en | Twitter Web Client | 0 | 0 | 0 | 1 | everyone | False | NaN | NaN | NaN | [{"start": 12, "end": 16, "probability": 0.9019, "type": "Person", "normalized_text": "David"}, {"start": 47, "end": 66, "probability": 0.9475, "type": "Person", "normalized_text": "David Foster Wallace"}] | NaN | [{"start": 104, "end": 117, "tag": "BillandDaves"}] | NaN | [{"start": 118, "end": 140, "url": "http://t.co/gU84ybdk2C", "expanded_url": "http://billanddavescocktailhour.com/a-few-footnotes-on-david-foster-wallace-putting-me-on-his-syllabus/", "display_url": "billanddavescocktailhour.com/a-few-footnote\u2026"}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 415297424 | 2011-11-18T04:44:11.000Z | billroorbach | Bill Roorbach | I'm a good writer with bad habits. Next novel is LUCKY TURTLE. Last three were THE GIRL OF THE LAKE,THE REMEDY FOR LOVE and LIFE AMONG GIANTS, all Algonquin Bks | NaN | NaN | NaN | NaN | [{"start": 0, "end": 23, "url": "https://t.co/Rchi3d2r2h", "expanded_url": "http://billanddavescocktailhour.com/", "display_url": "billanddavescocktailhour.com"}] | Western Maine, USA | 1.470842e+18 | https://pbs.twimg.com/profile_images/2507562193/9g6zj946bsc6xkeeon1m_normal.jpeg | False | 3107 | 1261 | 78 | 11306 | https://t.co/Rchi3d2r2h | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 28 | 270661455727165442 | 270661455727165442 | NaN | NaN | NaN | 15022464 | NaN | NaN | NaN | 2012-11-19 22:54:54+00:00 | Ayn Rand too, bro RT @SUPSLA: of couuuuuuuuurse david foster wallace is quoted. | en | TweetDeck | 0 | 0 | 0 | 0 | everyone | False | NaN | NaN | NaN | [{"start": 0, "end": 7, "probability": 0.6927, "type": "Person", "normalized_text": "Ayn Rand"}, {"start": 48, "end": 67, "probability": 0.7967, "type": "Person", "normalized_text": "david foster wallace"}] | NaN | NaN | [{"start": 21, "end": 28, "username": "supsla", "id": "42003947", "created_at": "2009-05-23T09:46:59.000Z", "description": "", "public_metrics": {"followers_count": 257, "following_count": 281, "tweet_count": 8311, "listed_count": 10}, "protected": false, "name": "in these unprecedented times", "verified": false, "url": "", "profile_image_url": "https://pbs.twimg.com/profile_images/12472297709... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 15022464 | 2008-06-05T19:46:53.000Z | stephaniemlee | Stephanie M. Lee | Science reporter, BuzzFeed News / not here right now / stephanie.lee@buzzfeed.com | NaN | NaN | NaN | NaN | [{"start": 0, "end": 23, "url": "https://t.co/G5wTIiUozJ", "expanded_url": "http://stephaniemlee.com", "display_url": "stephaniemlee.com"}] | San Francisco | 1.450152e+18 | https://pbs.twimg.com/profile_images/1466860232529743874/0J4IVS8E_normal.jpg | False | 22351 | 1972 | 916 | 18502 | https://t.co/G5wTIiUozJ | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
| 29 | 146330510422048768 | 146329543211368449 | 1.463295e+17 | NaN | NaN | 15644695 | 85877346.0 | NaN | NaN | 2011-12-12 20:48:07+00:00 | @MelodicRecords chillax brother, we all gud. Put another blunt on the barbie 'n' go wid th' flo bro. Dude man... http://t.co/q0RUmv12 | en | Twitter Web Client | 0 | 0 | 1 | 0 | everyone | False | NaN | NaN | NaN | NaN | NaN | NaN | [{"start": 0, "end": 15, "username": "MelodicRecords", "id": "85877346", "created_at": "2009-10-28T18:23:46.000Z", "description": "Independent Record Label - https://t.co/FxPLZYOQkn\nCheck out @MelodicEULabels for European Distribution, Press and Label Services.", "public_metrics": {"followers_count": 3644, "following_count": 2973, "tweet_count": 8403, "listed_count": 100}, "protected": false,... | [{"start": 113, "end": 133, "url": "http://t.co/q0RUmv12", "expanded_url": "http://www.nytimes.com/2011/08/21/magazine/another-thing-to-sort-of-pin-on-david-foster-wallace.html?pagewanted=all", "display_url": "nytimes.com/2011/08/21/mag\u2026"}] | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 15644695 | 2008-07-29T11:04:18.000Z | DrownedinSound | Drowned in Sound ⚓️ | Opinions On Music Since October 2000. An online community | NaN | NaN | NaN | NaN | [{"start": 0, "end": 23, "url": "https://t.co/JzYUcrN524", "expanded_url": "http://drownedinsound.com", "display_url": "drownedinsound.com"}] | London | 1.433813e+18 | https://pbs.twimg.com/profile_images/826686320881840128/Pgs_4vPo_normal.jpg | False | 101072 | 1873 | 2717 | 36341 | https://t.co/JzYUcrN524 | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2021-12-23T14:37:25+00:00 | https://api.twitter.com/2/tweets/search/all?expansions=author_id%2Cin_reply_to_user_id%2Creferenced_tweets.id%2Creferenced_tweets.id.author_id%2Centities.mentions.username%2Cattachments.poll_ids%2Cattachments.media_keys%2Cgeo.place_id&tweet.fields=attachments%2Cauthor_id%2Ccontext_annotations%2Cconversation_id%2Ccreated_at%2Centities%2Cgeo%2Cid%2Cin_reply_to_user_id%2Clang%2Cpublic_metrics%2Ct... | 2.8.2 | NaN |
If we ask for a list of all the columns in the DataFrame, we can see that there are more than 90 columns here!
tweets_df.columns
Index(['id', 'created_at', 'text', 'attachments.media',
'attachments.media_keys', 'attachments.poll.duration_minutes',
'attachments.poll.end_datetime', 'attachments.poll.id',
'attachments.poll.options', 'attachments.poll.voting_status',
'attachments.poll_ids', 'author.id', 'author.created_at',
'author.username', 'author.name', 'author.description',
'author.entities.description.cashtags',
'author.entities.description.hashtags',
'author.entities.description.mentions',
'author.entities.description.urls', 'author.entities.url.urls',
'author.location', 'author.pinned_tweet_id', 'author.profile_image_url',
'author.protected', 'author.public_metrics.followers_count',
'author.public_metrics.following_count',
'author.public_metrics.listed_count',
'author.public_metrics.tweet_count', 'author.url', 'author.verified',
'author.withheld.scope', 'author.withheld.copyright',
'author.withheld.country_codes', 'author_id', 'context_annotations',
'conversation_id', 'entities.annotations', 'entities.cashtags',
'entities.hashtags', 'entities.mentions', 'entities.urls',
'geo.coordinates.coordinates', 'geo.coordinates.type', 'geo.country',
'geo.country_code', 'geo.full_name', 'geo.geo.bbox', 'geo.geo.type',
'geo.id', 'geo.name', 'geo.place_id', 'geo.place_type',
'in_reply_to_user.id', 'in_reply_to_user.created_at',
'in_reply_to_user.username', 'in_reply_to_user.name',
'in_reply_to_user.description',
'in_reply_to_user.entities.description.cashtags',
'in_reply_to_user.entities.description.hashtags',
'in_reply_to_user.entities.description.mentions',
'in_reply_to_user.entities.description.urls',
'in_reply_to_user.entities.url.urls', 'in_reply_to_user.location',
'in_reply_to_user.pinned_tweet_id',
'in_reply_to_user.profile_image_url', 'in_reply_to_user.protected',
'in_reply_to_user.public_metrics.followers_count',
'in_reply_to_user.public_metrics.following_count',
'in_reply_to_user.public_metrics.listed_count',
'in_reply_to_user.public_metrics.tweet_count', 'in_reply_to_user.url',
'in_reply_to_user.verified', 'in_reply_to_user.withheld.scope',
'in_reply_to_user.withheld.copyright',
'in_reply_to_user.withheld.country_codes', 'in_reply_to_user_id',
'lang', 'possibly_sensitive', 'public_metrics.like_count',
'public_metrics.quote_count', 'public_metrics.reply_count',
'public_metrics.retweet_count', 'referenced_tweets', 'reply_settings',
'source', 'withheld.scope', 'withheld.copyright',
'withheld.country_codes', 'type', '__twarc.retrieved_at', '__twarc.url',
'__twarc.version', 'Unnamed: 93'],
dtype='object')
As you experiment with the query syntax provided by the Twitter API you should make a habit of scanning through your collected Twitter data to ensure that your API query and subsequent manipulations are returning the data that you expect and want. If you notice tweets you don’t expect return to examine your query to see if you can explain why those tweets are turning up. If you can’t find an adequate explanation you might want to ask in the Twitter Community Forum.
Extract Tweet and Media URLs#
We can make some Python functions that will create a tweet URL based on each tweet’s unique ID as well as extract an image URL if one exists.
# Make Tweet URL
def make_tweet_url(tweets):
# Get username
username = tweets[0]
# Get tweet ID
tweet_id = tweets[1]
# Make tweet URL
tweet_url = f"https://twitter.com/{username}/status/{tweet_id}"
return tweet_url
# Extract Image URL
from ast import literal_eval
def get_image_url(media):
# if not NaN or {}
if type(media) != float and media != '{}':
# Convert to an actual Python list, not just a string
media = literal_eval(media)
media = media[0]
# Extract media url if it exists
if 'url' in media.keys():
return media['url']
else:
return "No Image URL"
Here we apply the above Python functions to the relevant columns to create new columns.
tweets_df['tweet_url'] = tweets_df[['author.username', 'id']].apply(make_tweet_url, axis='columns')
tweets_df['media'] = tweets_df['attachments.media'].apply(get_image_url)
Rename and Select Columns#
To make the data more readable, we’re going to rename a number of columns.
tweets_df.rename(columns={'created_at': 'date',
'public_metrics.retweet_count': 'retweets',
'author.username': 'username',
'author.name': 'name',
'author.verified': 'verified',
'public_metrics.like_count': 'likes',
'public_metrics.quote_count': 'quotes',
'public_metrics.reply_count': 'replies',
'author.description': 'user_bio'},
inplace=True)
Then we’re only going to select the columns that we’re interested. Depending on your project and research question, you should change and customize these categories.
tweets_df = tweets_df[['date', 'username', 'name', 'verified', 'text', 'retweets',
'likes', 'replies', 'quotes', 'tweet_url', 'media', 'user_bio']]
Now we can view our more focused DataFrame!
tweets_df
| date | username | name | verified | text | retweets | likes | replies | quotes | tweet_url | media | user_bio | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2021-11-30 13:16:56+00:00 | TJCarpenterShow | Terry Wayne Carpenter, Jr. | True | It has little to do with the gender of the author, protagonist, etc. Olga Tokarczuk is just as appealing to male readers as David Foster Wallace (who is considered 'bro lit'). It seems to be more directly related, interestingly enough, to the postmodernist divide in literature. | 0 | 0 | 1 | 0 | https://twitter.com/TJCarpenterShow/status/1465671187497840642 | No Image URL | Writer; shitposting. |
| 1 | 2021-07-06 10:40:49+00:00 | JeyyLowe | Josh Lowe | True | @TomKealy2 @aveek18 @maybeavalon Imo the great twitter literature injustice is that it is david foster wallace and not him that is smeared as the dumb bro contemporary author | 0 | 2 | 2 | 0 | https://twitter.com/JeyyLowe/status/1412360883582418945 | No Image URL | Policy-focused content guy. (Mostly) ex-journalist. Mediating between evidence and action at global data institute for child safety @EdinburghUni. Views mine. |
| 2 | 2021-06-26 17:04:10+00:00 | adamdavidson | Adam Davidson | True | @page88 @IngrahamAngle I heard a tech bro quote a line about cruise ship wait staff from David Foster Wallace's A Supposedly Fun Thing and said it showed how DFW really believed in great customer service. | 0 | 11 | 1 | 0 | https://twitter.com/adamdavidson/status/1408833479304003589 | No Image URL | Sharing the lessons I’ve learned from @ThisAmerLife @NewYorker and my baby, @planetmoney on how to make storytelling your superpower at https://t.co/QyMS00u10R |
| 3 | 2020-10-06 21:23:56+00:00 | ben_geier | Goy Division/Jew Order | False | the guy who publicly makes a display of how much feminist literature he reads and waxes on how important bookshelf representation is at least 50% more likely to be a sexpest than the bro who just likes to vibe about david foster wallace and hemingway. this is science. https://t.co/QsvsVxBY15 | 12 | 98 | 2 | 1 | https://twitter.com/ben_geier/status/1313590839977947136 | No Image URL | Journalist, writer, Brooklyn trash. We’re all hypocrites, but you’re a patriot. Married to my wife, dad to a baby. |
| 4 | 2020-10-06 16:54:42+00:00 | ben_geier | Goy Division/Jew Order | False | the guy who publicly makes a display of how much feminist literature he reads and waxes on how important bookshelf representation is at least 50% more likely to be a sexpest than the bro who just likes to vibe about david foster wallace and hemingway. this is science. https://t.co/QsvsVxBY15 | 12 | 98 | 2 | 1 | https://twitter.com/ben_geier/status/1313523086424186881 | No Image URL | Journalist, writer, Brooklyn trash. We’re all hypocrites, but you’re a patriot. Married to my wife, dad to a baby. |
| 5 | 2020-08-25 00:52:37+00:00 | chrisdeville | Chris DeVille | True | david foster wallace bro conversation again? i feel like by this point in the discourse i need footnotes! (just a little "insider" dfw humor for ya) | 23 | 407 | 4 | 1 | https://twitter.com/chrisdeville/status/1298060678432010240 | No Image URL | Managing Editor, Stereogum // chris at stereogum dot com |
| 6 | 2020-08-24 19:06:25+00:00 | MaraWilson | Mara “Get Rid of the Nazis” Wilson | True | david foster wallace bro conversation again? i feel like by this point in the discourse i need footnotes! (just a little "insider" dfw humor for ya) | 23 | 407 | 4 | 1 | https://twitter.com/MaraWilson/status/1297973554986639360 | No Image URL | On Instagram and Cameo more these days. For info or press please contact Heidi@positivejampr.com. Buy my book WHERE AM I NOW? https://t.co/olmpPDMQk3 |
| 7 | 2020-08-20 15:18:35+00:00 | ben_a_goldfarb | Ben Goldfarb | True | (Gonna out myself as an insufferable millennial bro and say David Foster Wallace—his maximalism expands my sense of what's possible on the page, as does his notorious blend of academic and colloquial prose. I swear the copy of INFINITE JEST on my shelf is not a display piece.) | 0 | 14 | 1 | 0 | https://twitter.com/ben_a_goldfarb/status/1296466668898717696 | No Image URL | Independent journalist on the #roadecology beat. Author of EAGER, an award-winning book about beaver belief. |
| 8 | 2020-05-11 18:56:06+00:00 | MilesKlee | Miles Klee | True | This week for the MEL Review of Books, we had @leahrosenz talk to @adriennemiller about IN THE LAND OF MEN, a memoir of the dude snobbery she faced as the literary editor at Esquire while publishing the likes of David Foster Wallace: \nhttps://t.co/26WQYMgakO | 1 | 9 | 1 | 0 | https://twitter.com/MilesKlee/status/1259920233600479233 | No Image URL | my followers are of the highest quality |
| 9 | 2019-03-22 14:51:51+00:00 | BMcGfresh | Brendan McGuirk | False | "The Great White Male is rap's Grand Inquisitor, its idiot questioner, its Alien Other no less than Reds were for McCarthy." -- David Foster Wallace, on his forays into Dorchester & Roxbury's music scenes, 1989\n\n"I know bro, but still-" -- Brendan McGuirk, reflecting on it, 2019 https://t.co/lYJV5bU7yb | 0 | 1 | 1 | 0 | https://twitter.com/BMcGfresh/status/1109105414849921029 | No Image URL | checkpoint unlocked |
| 10 | 2018-12-20 15:44:17+00:00 | MEPFuller | Matt Fuller | True | Is—is Alexandria Ocasio-Cortez a David Foster Wallace bro? https://t.co/OcwGRUdWMV | 4 | 54 | 3 | 3 | https://twitter.com/MEPFuller/status/1075778924280471553 | No Image URL | Politics stuff at The Daily Beast. Take these tweets seriously but not literally. |
| 11 | 2018-05-13 02:15:17+00:00 | nandelabra | Nandini B. | True | I got kicked out of KGB Bar in the LES for arguing with a lit bro that David Foster Wallace is a better writer than Thomas Pynchon. https://t.co/iQLxduLtEN | 0 | 43 | 12 | 0 | https://twitter.com/nandelabra/status/995487617549512704 | No Image URL | writer | copy editor | bylines: Wired, Defector, TX Observer, Pacific Standard, Slate, The Week, Ebert Voices, Lit Hub, TNR, Harper’s et al. | she/her | |
| 12 | 2017-08-17 18:13:09+00:00 | thesarahkelly | sarah | True | UPDATE: I met a "Have you read David Foster Wallace?" bro at law school. It only took four days, fam. FOUR. | 1 | 12 | 2 | 0 | https://twitter.com/thesarahkelly/status/898246334804787202 | No Image URL | Editor, mostly copy, @sinow. Diversity fellow, @APSE_sportmedia. Previously: @WaPoExpress, @SBNation, @theeagle. Lawrence native, KU grad. Trajan sucks. |
| 13 | 2017-03-22 14:13:17+00:00 | theferocity | Saeed Jones | True | "David Foster Wallace is essentially the same as skiing and cigars now.” https://t.co/GPCbgdBL3e | 4 | 14 | 2 | 3 | https://twitter.com/theferocity/status/844552567522820096 | No Image URL | I’m chaotic and always right. ✨Forthcoming: ALIVE AT THE END OF THE WORLD, Fall 2022. ✨Previously: HOW WE FIGHT FOR OUR LIVES. Reps: @TuesdayAgency @SheedyLit. |
| 14 | 2016-08-03 17:24:14+00:00 | rebeccamakkai | Rebecca Makkai | True | New theory: Bernie Bro holdouts are exactly the same people as David Foster Wallace fanatics. Yes? | 0 | 14 | 2 | 0 | https://twitter.com/rebeccamakkai/status/760889024403873792 | No Image URL | Pulitzer & Nat'l Book Award finalist, winner of ALA Carnegie Medal for THE GREAT BELIEVERS. Artistic Director at @storystudio. She/her. Daughter of a refugee. |
| 15 | 2016-05-20 14:27:40+00:00 | MEPFuller | Matt Fuller | True | Am I a David Foster Wallace bro? Very well, I'm a David Foster Wallace bro. | 1 | 2 | 1 | 0 | https://twitter.com/MEPFuller/status/733665498148294657 | No Image URL | Politics stuff at The Daily Beast. Take these tweets seriously but not literally. |
| 16 | 2016-02-01 18:24:47+00:00 | deep_beige | Brendan james | True | David Foster Wallace sucks and this is a great review of interminable jest, via @Bro_Pair https://t.co/hxGFGY6D3Z | 0 | 6 | 0 | 0 | https://twitter.com/deep_beige/status/694224894805032964 | No Image URL | Co-host and producer @Blowbackpod. "The Great Vorelli" \nbjames0928@gmail.com |
| 17 | 2016-01-12 03:34:53+00:00 | Dooezer | Mary Dooe | True | "Bro stop being such a David Foster Wallace footnote" | 0 | 2 | 1 | 0 | https://twitter.com/Dooezer/status/686753187727044609 | No Image URL | podcast creator. MBA. quite contrary. founder of Dooe Diligence Media. past work @marketplace @wbur @nprwest @wgbh @harvardbiz @iheartradio. https://t.co/514RH9nvyk |
| 18 | 2015-09-17 00:33:07+00:00 | Fahrenthold | David Fahrenthold | True | Did Carly Fiorina just make a David Foster Wallace reference?\n\nIs Carly Fiorina a David Foster Wallace bro?? | 5 | 12 | 0 | 0 | https://twitter.com/Fahrenthold/status/644308060937265152 | No Image URL | Washington Post reporter, covering former President Trump's businesses. MSNBC contributor. If you don't want it printed, don't let it happen. |
| 19 | 2015-09-17 00:32:50+00:00 | ColinACurtis | Colin Curtis | True | Did Carly Fiorina just make a David Foster Wallace reference?\n\nIs Carly Fiorina a David Foster Wallace bro?? | 5 | 12 | 0 | 0 | https://twitter.com/ColinACurtis/status/644307992901517312 | No Image URL | Dem hack | Alum of campaigns, legislatures, & unions | BBQ enthusiast | Occasional writer | Gamer | Royals & Chiefs fan | Dotte / Kansan turned DC dweller |
| 20 | 2015-09-17 00:32:29+00:00 | MEPFuller | Matt Fuller | True | Did Carly Fiorina just make a David Foster Wallace reference?\n\nIs Carly Fiorina a David Foster Wallace bro?? | 5 | 12 | 0 | 0 | https://twitter.com/MEPFuller/status/644307901830561793 | No Image URL | Politics stuff at The Daily Beast. Take these tweets seriously but not literally. |
| 21 | 2015-08-14 11:31:24+00:00 | PublishersWkly | Publishers Weekly | True | "David Foster Wallace was not a bro: Let’s not paint the writer with the same brush as his fans" | Salon http://t.co/t4FqgmoyVz | 10 | 19 | 0 | 0 | https://twitter.com/PublishersWkly/status/632152536636608512 | No Image URL | The international source for book publishing and bookselling news, reviews, and information. |
| 22 | 2015-08-13 20:53:02+00:00 | Salon | Salon | True | David Foster Wallace was *not* a bro: Don't paint the writer with the same brush as his fans http://t.co/vZvwEien22 | 10 | 16 | 3 | 0 | https://twitter.com/Salon/status/631931489769390080 | No Image URL | The original online source for news, politics and entertainment | Find us on Instagram & TikTok: salonofficial | Subscribe to our newsletters linked below |
| 23 | 2015-08-13 14:02:23+00:00 | Gwen_UsBeauty | Gwen Flamberg | True | You probably know a bro who says he loves David Foster Wallace: http://t.co/3KfOlw2UR6 http://t.co/xNI9tbF02p | 7 | 5 | 0 | 0 | https://twitter.com/Gwen_UsBeauty/status/631828145105162240 | https://pbs.twimg.com/media/CMSx-8XWcAAnkK-.jpg | Beauty, style and lifestyle influencer. Red Carpet beauty and style expert and makeup addict. Tweets are my own. |
| 24 | 2015-08-13 13:52:26+00:00 | Blumsteinboy | Ian Harrison | True | You probably know a bro who says he loves David Foster Wallace: http://t.co/3KfOlw2UR6 http://t.co/xNI9tbF02p | 7 | 5 | 0 | 0 | https://twitter.com/Blumsteinboy/status/631825643441901568 | https://pbs.twimg.com/media/CMSx-8XWcAAnkK-.jpg | Decolonize it all. 🇬🇾 |
| 25 | 2015-08-13 13:52:02+00:00 | TheCut | The Cut | True | You probably know a bro who says he loves David Foster Wallace: http://t.co/3KfOlw2UR6 http://t.co/xNI9tbF02p | 7 | 5 | 0 | 0 | https://twitter.com/TheCut/status/631825543202213889 | https://pbs.twimg.com/media/CMSx-8XWcAAnkK-.jpg | Style. Self. Culture. Power.\nFind us on Instagram: @TheCut\nSubscribe to New York for more: https://t.co/1OtjTJftYM |
| 26 | 2015-08-13 13:31:24+00:00 | sts10 | Sam Schlinkert | True | All men are bad but are David Foster Wallace fans a special kind of bad? http://t.co/w5KOvJBcui http://t.co/yBhOr3aPjy | 8 | 27 | 3 | 0 | https://twitter.com/sts10/status/631820349290774528 | https://pbs.twimg.com/media/CMStMPvXAAA5a1J.jpg | Content Programming Editor at @CNNplus. Sometimes programmer. |
| 27 | 2014-12-17 01:00:01+00:00 | billroorbach | Bill Roorbach | True | My blog bro David (@BDsCocktailHour) reacts to David Foster Wallace's teaching Gessner. With footnotes. #BillandDaves http://t.co/gU84ybdk2C | 1 | 0 | 0 | 0 | https://twitter.com/billroorbach/status/545020559248343040 | No Image URL | I'm a good writer with bad habits. Next novel is LUCKY TURTLE. Last three were THE GIRL OF THE LAKE,THE REMEDY FOR LOVE and LIFE AMONG GIANTS, all Algonquin Bks |
| 28 | 2012-11-19 22:54:54+00:00 | stephaniemlee | Stephanie M. Lee | True | Ayn Rand too, bro RT @SUPSLA: of couuuuuuuuurse david foster wallace is quoted. | 0 | 0 | 0 | 0 | https://twitter.com/stephaniemlee/status/270661455727165442 | No Image URL | Science reporter, BuzzFeed News / not here right now / stephanie.lee@buzzfeed.com |
| 29 | 2011-12-12 20:48:07+00:00 | DrownedinSound | Drowned in Sound ⚓️ | True | @MelodicRecords chillax brother, we all gud. Put another blunt on the barbie 'n' go wid th' flo bro. Dude man... http://t.co/q0RUmv12 | 0 | 0 | 1 | 0 | https://twitter.com/DrownedinSound/status/146330510422048768 | No Image URL | Opinions On Music Since October 2000. An online community |
Sort By Top Retweets#
We can sort by number of retweets to see the most circulated tweets. Let’s examine the top 5.
tweets_df.sort_values(by='retweets', ascending=False)[:5]
| date | username | name | verified | text | retweets | likes | replies | quotes | tweet_url | media | user_bio | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 2020-08-25 00:52:37+00:00 | chrisdeville | Chris DeVille | True | david foster wallace bro conversation again? i feel like by this point in the discourse i need footnotes! (just a little "insider" dfw humor for ya) | 23 | 407 | 4 | 1 | https://twitter.com/chrisdeville/status/1298060678432010240 | No Image URL | Managing Editor, Stereogum // chris at stereogum dot com |
| 6 | 2020-08-24 19:06:25+00:00 | MaraWilson | Mara “Get Rid of the Nazis” Wilson | True | david foster wallace bro conversation again? i feel like by this point in the discourse i need footnotes! (just a little "insider" dfw humor for ya) | 23 | 407 | 4 | 1 | https://twitter.com/MaraWilson/status/1297973554986639360 | No Image URL | On Instagram and Cameo more these days. For info or press please contact Heidi@positivejampr.com. Buy my book WHERE AM I NOW? https://t.co/olmpPDMQk3 |
| 3 | 2020-10-06 21:23:56+00:00 | ben_geier | Goy Division/Jew Order | False | the guy who publicly makes a display of how much feminist literature he reads and waxes on how important bookshelf representation is at least 50% more likely to be a sexpest than the bro who just likes to vibe about david foster wallace and hemingway. this is science. https://t.co/QsvsVxBY15 | 12 | 98 | 2 | 1 | https://twitter.com/ben_geier/status/1313590839977947136 | No Image URL | Journalist, writer, Brooklyn trash. We’re all hypocrites, but you’re a patriot. Married to my wife, dad to a baby. |
| 4 | 2020-10-06 16:54:42+00:00 | ben_geier | Goy Division/Jew Order | False | the guy who publicly makes a display of how much feminist literature he reads and waxes on how important bookshelf representation is at least 50% more likely to be a sexpest than the bro who just likes to vibe about david foster wallace and hemingway. this is science. https://t.co/QsvsVxBY15 | 12 | 98 | 2 | 1 | https://twitter.com/ben_geier/status/1313523086424186881 | No Image URL | Journalist, writer, Brooklyn trash. We’re all hypocrites, but you’re a patriot. Married to my wife, dad to a baby. |
| 21 | 2015-08-14 11:31:24+00:00 | PublishersWkly | Publishers Weekly | True | "David Foster Wallace was not a bro: Let’s not paint the writer with the same brush as his fans" | Salon http://t.co/t4FqgmoyVz | 10 | 19 | 0 | 0 | https://twitter.com/PublishersWkly/status/632152536636608512 | No Image URL | The international source for book publishing and bookselling news, reviews, and information. |
Here is the most retweeted tweet in this dataset:
david foster wallace bro conversation again? i feel like by this point in the discourse i need footnotes! (just a little "insider" dfw humor for ya)
— David Grossman (@davidgross_man) August 24, 2020
Sort By Date#
We can sort from the earliest tweets to the latest tweets. Let’s examine the earliest 5 tweets.
tweets_df.sort_values(by='date', ascending=True)[:5]
| date | username | name | verified | text | retweets | likes | replies | quotes | tweet_url | media | user_bio | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 29 | 2011-12-12 20:48:07+00:00 | DrownedinSound | Drowned in Sound ⚓️ | True | @MelodicRecords chillax brother, we all gud. Put another blunt on the barbie 'n' go wid th' flo bro. Dude man... http://t.co/q0RUmv12 | 0 | 0 | 1 | 0 | https://twitter.com/DrownedinSound/status/146330510422048768 | No Image URL | Opinions On Music Since October 2000. An online community |
| 28 | 2012-11-19 22:54:54+00:00 | stephaniemlee | Stephanie M. Lee | True | Ayn Rand too, bro RT @SUPSLA: of couuuuuuuuurse david foster wallace is quoted. | 0 | 0 | 0 | 0 | https://twitter.com/stephaniemlee/status/270661455727165442 | No Image URL | Science reporter, BuzzFeed News / not here right now / stephanie.lee@buzzfeed.com |
| 27 | 2014-12-17 01:00:01+00:00 | billroorbach | Bill Roorbach | True | My blog bro David (@BDsCocktailHour) reacts to David Foster Wallace's teaching Gessner. With footnotes. #BillandDaves http://t.co/gU84ybdk2C | 1 | 0 | 0 | 0 | https://twitter.com/billroorbach/status/545020559248343040 | No Image URL | I'm a good writer with bad habits. Next novel is LUCKY TURTLE. Last three were THE GIRL OF THE LAKE,THE REMEDY FOR LOVE and LIFE AMONG GIANTS, all Algonquin Bks |
| 26 | 2015-08-13 13:31:24+00:00 | sts10 | Sam Schlinkert | True | All men are bad but are David Foster Wallace fans a special kind of bad? http://t.co/w5KOvJBcui http://t.co/yBhOr3aPjy | 8 | 27 | 3 | 0 | https://twitter.com/sts10/status/631820349290774528 | https://pbs.twimg.com/media/CMStMPvXAAA5a1J.jpg | Content Programming Editor at @CNNplus. Sometimes programmer. |
| 25 | 2015-08-13 13:52:02+00:00 | TheCut | The Cut | True | You probably know a bro who says he loves David Foster Wallace: http://t.co/3KfOlw2UR6 http://t.co/xNI9tbF02p | 7 | 5 | 0 | 0 | https://twitter.com/TheCut/status/631825543202213889 | https://pbs.twimg.com/media/CMSx-8XWcAAnkK-.jpg | Style. Self. Culture. Power.\nFind us on Instagram: @TheCut\nSubscribe to New York for more: https://t.co/1OtjTJftYM |
The earliest tweet in this dataset is from the music label Melodic Records:
@MelodicRecords chillax brother, we all gud. Put another blunt on the barbie 'n' go wid th' flo bro. Dude man... http://t.co/q0RUmv12
— Drowned in Sound ⚓️ (@DrownedinSound) December 12, 2011
Plot Tweets Over Time#
An easy way to create a plot of tweets over time is to add a column with a 1 for every row, which we can use to count how many tweets were published per day, week, month, or year.
tweets_df = tweets_df.assign(count=1)
We also need to set the date column to the index so we can do some special date manipulations.
tweets_df = tweets_df.set_index('date')
tweets_df
| username | name | verified | text | retweets | likes | replies | quotes | tweet_url | media | user_bio | count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | ||||||||||||
| 2021-11-30 13:16:56+00:00 | TJCarpenterShow | Terry Wayne Carpenter, Jr. | True | It has little to do with the gender of the author, protagonist, etc. Olga Tokarczuk is just as appealing to male readers as David Foster Wallace (who is considered 'bro lit'). It seems to be more directly related, interestingly enough, to the postmodernist divide in literature. | 0 | 0 | 1 | 0 | https://twitter.com/TJCarpenterShow/status/1465671187497840642 | No Image URL | Writer; shitposting. | 1 |
| 2021-07-06 10:40:49+00:00 | JeyyLowe | Josh Lowe | True | @TomKealy2 @aveek18 @maybeavalon Imo the great twitter literature injustice is that it is david foster wallace and not him that is smeared as the dumb bro contemporary author | 0 | 2 | 2 | 0 | https://twitter.com/JeyyLowe/status/1412360883582418945 | No Image URL | Policy-focused content guy. (Mostly) ex-journalist. Mediating between evidence and action at global data institute for child safety @EdinburghUni. Views mine. | 1 |
| 2021-06-26 17:04:10+00:00 | adamdavidson | Adam Davidson | True | @page88 @IngrahamAngle I heard a tech bro quote a line about cruise ship wait staff from David Foster Wallace's A Supposedly Fun Thing and said it showed how DFW really believed in great customer service. | 0 | 11 | 1 | 0 | https://twitter.com/adamdavidson/status/1408833479304003589 | No Image URL | Sharing the lessons I’ve learned from @ThisAmerLife @NewYorker and my baby, @planetmoney on how to make storytelling your superpower at https://t.co/QyMS00u10R | 1 |
| 2020-10-06 21:23:56+00:00 | ben_geier | Goy Division/Jew Order | False | the guy who publicly makes a display of how much feminist literature he reads and waxes on how important bookshelf representation is at least 50% more likely to be a sexpest than the bro who just likes to vibe about david foster wallace and hemingway. this is science. https://t.co/QsvsVxBY15 | 12 | 98 | 2 | 1 | https://twitter.com/ben_geier/status/1313590839977947136 | No Image URL | Journalist, writer, Brooklyn trash. We’re all hypocrites, but you’re a patriot. Married to my wife, dad to a baby. | 1 |
| 2020-10-06 16:54:42+00:00 | ben_geier | Goy Division/Jew Order | False | the guy who publicly makes a display of how much feminist literature he reads and waxes on how important bookshelf representation is at least 50% more likely to be a sexpest than the bro who just likes to vibe about david foster wallace and hemingway. this is science. https://t.co/QsvsVxBY15 | 12 | 98 | 2 | 1 | https://twitter.com/ben_geier/status/1313523086424186881 | No Image URL | Journalist, writer, Brooklyn trash. We’re all hypocrites, but you’re a patriot. Married to my wife, dad to a baby. | 1 |
| 2020-08-25 00:52:37+00:00 | chrisdeville | Chris DeVille | True | david foster wallace bro conversation again? i feel like by this point in the discourse i need footnotes! (just a little "insider" dfw humor for ya) | 23 | 407 | 4 | 1 | https://twitter.com/chrisdeville/status/1298060678432010240 | No Image URL | Managing Editor, Stereogum // chris at stereogum dot com | 1 |
| 2020-08-24 19:06:25+00:00 | MaraWilson | Mara “Get Rid of the Nazis” Wilson | True | david foster wallace bro conversation again? i feel like by this point in the discourse i need footnotes! (just a little "insider" dfw humor for ya) | 23 | 407 | 4 | 1 | https://twitter.com/MaraWilson/status/1297973554986639360 | No Image URL | On Instagram and Cameo more these days. For info or press please contact Heidi@positivejampr.com. Buy my book WHERE AM I NOW? https://t.co/olmpPDMQk3 | 1 |
| 2020-08-20 15:18:35+00:00 | ben_a_goldfarb | Ben Goldfarb | True | (Gonna out myself as an insufferable millennial bro and say David Foster Wallace—his maximalism expands my sense of what's possible on the page, as does his notorious blend of academic and colloquial prose. I swear the copy of INFINITE JEST on my shelf is not a display piece.) | 0 | 14 | 1 | 0 | https://twitter.com/ben_a_goldfarb/status/1296466668898717696 | No Image URL | Independent journalist on the #roadecology beat. Author of EAGER, an award-winning book about beaver belief. | 1 |
| 2020-05-11 18:56:06+00:00 | MilesKlee | Miles Klee | True | This week for the MEL Review of Books, we had @leahrosenz talk to @adriennemiller about IN THE LAND OF MEN, a memoir of the dude snobbery she faced as the literary editor at Esquire while publishing the likes of David Foster Wallace: \nhttps://t.co/26WQYMgakO | 1 | 9 | 1 | 0 | https://twitter.com/MilesKlee/status/1259920233600479233 | No Image URL | my followers are of the highest quality | 1 |
| 2019-03-22 14:51:51+00:00 | BMcGfresh | Brendan McGuirk | False | "The Great White Male is rap's Grand Inquisitor, its idiot questioner, its Alien Other no less than Reds were for McCarthy." -- David Foster Wallace, on his forays into Dorchester & Roxbury's music scenes, 1989\n\n"I know bro, but still-" -- Brendan McGuirk, reflecting on it, 2019 https://t.co/lYJV5bU7yb | 0 | 1 | 1 | 0 | https://twitter.com/BMcGfresh/status/1109105414849921029 | No Image URL | checkpoint unlocked | 1 |
| 2018-12-20 15:44:17+00:00 | MEPFuller | Matt Fuller | True | Is—is Alexandria Ocasio-Cortez a David Foster Wallace bro? https://t.co/OcwGRUdWMV | 4 | 54 | 3 | 3 | https://twitter.com/MEPFuller/status/1075778924280471553 | No Image URL | Politics stuff at The Daily Beast. Take these tweets seriously but not literally. | 1 |
| 2018-05-13 02:15:17+00:00 | nandelabra | Nandini B. | True | I got kicked out of KGB Bar in the LES for arguing with a lit bro that David Foster Wallace is a better writer than Thomas Pynchon. https://t.co/iQLxduLtEN | 0 | 43 | 12 | 0 | https://twitter.com/nandelabra/status/995487617549512704 | No Image URL | writer | copy editor | bylines: Wired, Defector, TX Observer, Pacific Standard, Slate, The Week, Ebert Voices, Lit Hub, TNR, Harper’s et al. | she/her | | 1 |
| 2017-08-17 18:13:09+00:00 | thesarahkelly | sarah | True | UPDATE: I met a "Have you read David Foster Wallace?" bro at law school. It only took four days, fam. FOUR. | 1 | 12 | 2 | 0 | https://twitter.com/thesarahkelly/status/898246334804787202 | No Image URL | Editor, mostly copy, @sinow. Diversity fellow, @APSE_sportmedia. Previously: @WaPoExpress, @SBNation, @theeagle. Lawrence native, KU grad. Trajan sucks. | 1 |
| 2017-03-22 14:13:17+00:00 | theferocity | Saeed Jones | True | "David Foster Wallace is essentially the same as skiing and cigars now.” https://t.co/GPCbgdBL3e | 4 | 14 | 2 | 3 | https://twitter.com/theferocity/status/844552567522820096 | No Image URL | I’m chaotic and always right. ✨Forthcoming: ALIVE AT THE END OF THE WORLD, Fall 2022. ✨Previously: HOW WE FIGHT FOR OUR LIVES. Reps: @TuesdayAgency @SheedyLit. | 1 |
| 2016-08-03 17:24:14+00:00 | rebeccamakkai | Rebecca Makkai | True | New theory: Bernie Bro holdouts are exactly the same people as David Foster Wallace fanatics. Yes? | 0 | 14 | 2 | 0 | https://twitter.com/rebeccamakkai/status/760889024403873792 | No Image URL | Pulitzer & Nat'l Book Award finalist, winner of ALA Carnegie Medal for THE GREAT BELIEVERS. Artistic Director at @storystudio. She/her. Daughter of a refugee. | 1 |
| 2016-05-20 14:27:40+00:00 | MEPFuller | Matt Fuller | True | Am I a David Foster Wallace bro? Very well, I'm a David Foster Wallace bro. | 1 | 2 | 1 | 0 | https://twitter.com/MEPFuller/status/733665498148294657 | No Image URL | Politics stuff at The Daily Beast. Take these tweets seriously but not literally. | 1 |
| 2016-02-01 18:24:47+00:00 | deep_beige | Brendan james | True | David Foster Wallace sucks and this is a great review of interminable jest, via @Bro_Pair https://t.co/hxGFGY6D3Z | 0 | 6 | 0 | 0 | https://twitter.com/deep_beige/status/694224894805032964 | No Image URL | Co-host and producer @Blowbackpod. "The Great Vorelli" \nbjames0928@gmail.com | 1 |
| 2016-01-12 03:34:53+00:00 | Dooezer | Mary Dooe | True | "Bro stop being such a David Foster Wallace footnote" | 0 | 2 | 1 | 0 | https://twitter.com/Dooezer/status/686753187727044609 | No Image URL | podcast creator. MBA. quite contrary. founder of Dooe Diligence Media. past work @marketplace @wbur @nprwest @wgbh @harvardbiz @iheartradio. https://t.co/514RH9nvyk | 1 |
| 2015-09-17 00:33:07+00:00 | Fahrenthold | David Fahrenthold | True | Did Carly Fiorina just make a David Foster Wallace reference?\n\nIs Carly Fiorina a David Foster Wallace bro?? | 5 | 12 | 0 | 0 | https://twitter.com/Fahrenthold/status/644308060937265152 | No Image URL | Washington Post reporter, covering former President Trump's businesses. MSNBC contributor. If you don't want it printed, don't let it happen. | 1 |
| 2015-09-17 00:32:50+00:00 | ColinACurtis | Colin Curtis | True | Did Carly Fiorina just make a David Foster Wallace reference?\n\nIs Carly Fiorina a David Foster Wallace bro?? | 5 | 12 | 0 | 0 | https://twitter.com/ColinACurtis/status/644307992901517312 | No Image URL | Dem hack | Alum of campaigns, legislatures, & unions | BBQ enthusiast | Occasional writer | Gamer | Royals & Chiefs fan | Dotte / Kansan turned DC dweller | 1 |
| 2015-09-17 00:32:29+00:00 | MEPFuller | Matt Fuller | True | Did Carly Fiorina just make a David Foster Wallace reference?\n\nIs Carly Fiorina a David Foster Wallace bro?? | 5 | 12 | 0 | 0 | https://twitter.com/MEPFuller/status/644307901830561793 | No Image URL | Politics stuff at The Daily Beast. Take these tweets seriously but not literally. | 1 |
| 2015-08-14 11:31:24+00:00 | PublishersWkly | Publishers Weekly | True | "David Foster Wallace was not a bro: Let’s not paint the writer with the same brush as his fans" | Salon http://t.co/t4FqgmoyVz | 10 | 19 | 0 | 0 | https://twitter.com/PublishersWkly/status/632152536636608512 | No Image URL | The international source for book publishing and bookselling news, reviews, and information. | 1 |
| 2015-08-13 20:53:02+00:00 | Salon | Salon | True | David Foster Wallace was *not* a bro: Don't paint the writer with the same brush as his fans http://t.co/vZvwEien22 | 10 | 16 | 3 | 0 | https://twitter.com/Salon/status/631931489769390080 | No Image URL | The original online source for news, politics and entertainment | Find us on Instagram & TikTok: salonofficial | Subscribe to our newsletters linked below | 1 |
| 2015-08-13 14:02:23+00:00 | Gwen_UsBeauty | Gwen Flamberg | True | You probably know a bro who says he loves David Foster Wallace: http://t.co/3KfOlw2UR6 http://t.co/xNI9tbF02p | 7 | 5 | 0 | 0 | https://twitter.com/Gwen_UsBeauty/status/631828145105162240 | https://pbs.twimg.com/media/CMSx-8XWcAAnkK-.jpg | Beauty, style and lifestyle influencer. Red Carpet beauty and style expert and makeup addict. Tweets are my own. | 1 |
| 2015-08-13 13:52:26+00:00 | Blumsteinboy | Ian Harrison | True | You probably know a bro who says he loves David Foster Wallace: http://t.co/3KfOlw2UR6 http://t.co/xNI9tbF02p | 7 | 5 | 0 | 0 | https://twitter.com/Blumsteinboy/status/631825643441901568 | https://pbs.twimg.com/media/CMSx-8XWcAAnkK-.jpg | Decolonize it all. 🇬🇾 | 1 |
| 2015-08-13 13:52:02+00:00 | TheCut | The Cut | True | You probably know a bro who says he loves David Foster Wallace: http://t.co/3KfOlw2UR6 http://t.co/xNI9tbF02p | 7 | 5 | 0 | 0 | https://twitter.com/TheCut/status/631825543202213889 | https://pbs.twimg.com/media/CMSx-8XWcAAnkK-.jpg | Style. Self. Culture. Power.\nFind us on Instagram: @TheCut\nSubscribe to New York for more: https://t.co/1OtjTJftYM | 1 |
| 2015-08-13 13:31:24+00:00 | sts10 | Sam Schlinkert | True | All men are bad but are David Foster Wallace fans a special kind of bad? http://t.co/w5KOvJBcui http://t.co/yBhOr3aPjy | 8 | 27 | 3 | 0 | https://twitter.com/sts10/status/631820349290774528 | https://pbs.twimg.com/media/CMStMPvXAAA5a1J.jpg | Content Programming Editor at @CNNplus. Sometimes programmer. | 1 |
| 2014-12-17 01:00:01+00:00 | billroorbach | Bill Roorbach | True | My blog bro David (@BDsCocktailHour) reacts to David Foster Wallace's teaching Gessner. With footnotes. #BillandDaves http://t.co/gU84ybdk2C | 1 | 0 | 0 | 0 | https://twitter.com/billroorbach/status/545020559248343040 | No Image URL | I'm a good writer with bad habits. Next novel is LUCKY TURTLE. Last three were THE GIRL OF THE LAKE,THE REMEDY FOR LOVE and LIFE AMONG GIANTS, all Algonquin Bks | 1 |
| 2012-11-19 22:54:54+00:00 | stephaniemlee | Stephanie M. Lee | True | Ayn Rand too, bro RT @SUPSLA: of couuuuuuuuurse david foster wallace is quoted. | 0 | 0 | 0 | 0 | https://twitter.com/stephaniemlee/status/270661455727165442 | No Image URL | Science reporter, BuzzFeed News / not here right now / stephanie.lee@buzzfeed.com | 1 |
| 2011-12-12 20:48:07+00:00 | DrownedinSound | Drowned in Sound ⚓️ | True | @MelodicRecords chillax brother, we all gud. Put another blunt on the barbie 'n' go wid th' flo bro. Dude man... http://t.co/q0RUmv12 | 0 | 0 | 1 | 0 | https://twitter.com/DrownedinSound/status/146330510422048768 | No Image URL | Opinions On Music Since October 2000. An online community | 1 |
Because our index is a datetime value, we can use the special Pandas method .resample() to group the tweets by month, add them up, and plot them over time.
tweets_df['count'].resample('M').sum()\
.plot(title='"David Foster Wallace Bro"\n Tweets from Verified Accounts');
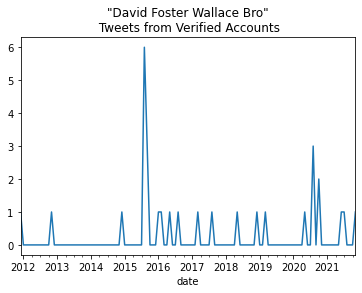
Display Links and Images in Twitter Data#
To display links and images in our DataFrame, we can convert the image URL into an HTML image tag, and we can display our DataFrame as an HTML object with the HTML module.
from IPython.core.display import HTML
def get_image_html(link):
# check to see if the media category has an image URL
if link != "No Image URL":
# format the image url as an HTML image
image_html = f"<a href='{link}'>'<img src='{link}' width='500px'></a> "
return image_html
else:
return "No Image URL"
# Apply the above function to the media column
tweets_df['media']= tweets_df['media'].apply(get_image_html)
View images
HTML(tweets_df[['media', 'text']].sort_values(by='media').to_html(render_links=True, escape=False))
| media | text | |
|---|---|---|
| date | ||
| 2015-08-13 13:31:24+00:00 | ' |
All men are bad but are David Foster Wallace fans a special kind of bad? http://t.co/w5KOvJBcui http://t.co/yBhOr3aPjy |
| 2015-08-13 13:52:02+00:00 | ' |
You probably know a bro who says he loves David Foster Wallace: http://t.co/3KfOlw2UR6 http://t.co/xNI9tbF02p |
| 2015-08-13 13:52:26+00:00 | ' |
You probably know a bro who says he loves David Foster Wallace: http://t.co/3KfOlw2UR6 http://t.co/xNI9tbF02p |
| 2015-08-13 14:02:23+00:00 | ' |
You probably know a bro who says he loves David Foster Wallace: http://t.co/3KfOlw2UR6 http://t.co/xNI9tbF02p |
| 2021-11-30 13:16:56+00:00 | No Image URL | It has little to do with the gender of the author, protagonist, etc. Olga Tokarczuk is just as appealing to male readers as David Foster Wallace (who is considered 'bro lit'). It seems to be more directly related, interestingly enough, to the postmodernist divide in literature. |
| 2014-12-17 01:00:01+00:00 | No Image URL | My blog bro David (@BDsCocktailHour) reacts to David Foster Wallace's teaching Gessner. With footnotes. #BillandDaves http://t.co/gU84ybdk2C |
| 2015-08-13 20:53:02+00:00 | No Image URL | David Foster Wallace was *not* a bro: Don't paint the writer with the same brush as his fans http://t.co/vZvwEien22 |
| 2015-08-14 11:31:24+00:00 | No Image URL | "David Foster Wallace was not a bro: Let’s not paint the writer with the same brush as his fans" | Salon http://t.co/t4FqgmoyVz |
| 2015-09-17 00:32:29+00:00 | No Image URL | Did Carly Fiorina just make a David Foster Wallace reference?\n\nIs Carly Fiorina a David Foster Wallace bro?? |
| 2015-09-17 00:32:50+00:00 | No Image URL | Did Carly Fiorina just make a David Foster Wallace reference?\n\nIs Carly Fiorina a David Foster Wallace bro?? |
| 2015-09-17 00:33:07+00:00 | No Image URL | Did Carly Fiorina just make a David Foster Wallace reference?\n\nIs Carly Fiorina a David Foster Wallace bro?? |
| 2016-01-12 03:34:53+00:00 | No Image URL | "Bro stop being such a David Foster Wallace footnote" |
| 2016-02-01 18:24:47+00:00 | No Image URL | David Foster Wallace sucks and this is a great review of interminable jest, via @Bro_Pair https://t.co/hxGFGY6D3Z |
| 2016-05-20 14:27:40+00:00 | No Image URL | Am I a David Foster Wallace bro? Very well, I'm a David Foster Wallace bro. |
| 2016-08-03 17:24:14+00:00 | No Image URL | New theory: Bernie Bro holdouts are exactly the same people as David Foster Wallace fanatics. Yes? |
| 2017-03-22 14:13:17+00:00 | No Image URL | "David Foster Wallace is essentially the same as skiing and cigars now.” https://t.co/GPCbgdBL3e |
| 2017-08-17 18:13:09+00:00 | No Image URL | UPDATE: I met a "Have you read David Foster Wallace?" bro at law school. It only took four days, fam. FOUR. |
| 2018-05-13 02:15:17+00:00 | No Image URL | I got kicked out of KGB Bar in the LES for arguing with a lit bro that David Foster Wallace is a better writer than Thomas Pynchon. https://t.co/iQLxduLtEN |
| 2018-12-20 15:44:17+00:00 | No Image URL | Is—is Alexandria Ocasio-Cortez a David Foster Wallace bro? https://t.co/OcwGRUdWMV |
| 2019-03-22 14:51:51+00:00 | No Image URL | "The Great White Male is rap's Grand Inquisitor, its idiot questioner, its Alien Other no less than Reds were for McCarthy." -- David Foster Wallace, on his forays into Dorchester & Roxbury's music scenes, 1989\n\n"I know bro, but still-" -- Brendan McGuirk, reflecting on it, 2019 https://t.co/lYJV5bU7yb |
| 2020-05-11 18:56:06+00:00 | No Image URL | This week for the MEL Review of Books, we had @leahrosenz talk to @adriennemiller about IN THE LAND OF MEN, a memoir of the dude snobbery she faced as the literary editor at Esquire while publishing the likes of David Foster Wallace: \nhttps://t.co/26WQYMgakO |
| 2020-08-20 15:18:35+00:00 | No Image URL | (Gonna out myself as an insufferable millennial bro and say David Foster Wallace—his maximalism expands my sense of what's possible on the page, as does his notorious blend of academic and colloquial prose. I swear the copy of INFINITE JEST on my shelf is not a display piece.) |
| 2020-08-24 19:06:25+00:00 | No Image URL | david foster wallace bro conversation again? i feel like by this point in the discourse i need footnotes! (just a little "insider" dfw humor for ya) |
| 2020-08-25 00:52:37+00:00 | No Image URL | david foster wallace bro conversation again? i feel like by this point in the discourse i need footnotes! (just a little "insider" dfw humor for ya) |
| 2020-10-06 16:54:42+00:00 | No Image URL | the guy who publicly makes a display of how much feminist literature he reads and waxes on how important bookshelf representation is at least 50% more likely to be a sexpest than the bro who just likes to vibe about david foster wallace and hemingway. this is science. https://t.co/QsvsVxBY15 |
| 2020-10-06 21:23:56+00:00 | No Image URL | the guy who publicly makes a display of how much feminist literature he reads and waxes on how important bookshelf representation is at least 50% more likely to be a sexpest than the bro who just likes to vibe about david foster wallace and hemingway. this is science. https://t.co/QsvsVxBY15 |
| 2021-06-26 17:04:10+00:00 | No Image URL | @page88 @IngrahamAngle I heard a tech bro quote a line about cruise ship wait staff from David Foster Wallace's A Supposedly Fun Thing and said it showed how DFW really believed in great customer service. |
| 2021-07-06 10:40:49+00:00 | No Image URL | @TomKealy2 @aveek18 @maybeavalon Imo the great twitter literature injustice is that it is david foster wallace and not him that is smeared as the dumb bro contemporary author |
| 2012-11-19 22:54:54+00:00 | No Image URL | Ayn Rand too, bro RT @SUPSLA: of couuuuuuuuurse david foster wallace is quoted. |
| 2011-12-12 20:48:07+00:00 | No Image URL | @MelodicRecords chillax brother, we all gud. Put another blunt on the barbie 'n' go wid th' flo bro. Dude man... http://t.co/q0RUmv12 |
View tweet links
HTML(tweets_df[['tweet_url', 'text', 'retweets']].sort_values(by='retweets', ascending=False).to_html(render_links=True, escape=False))
| tweet_url | text | retweets | |
|---|---|---|---|
| date | |||
| 2020-08-25 00:52:37+00:00 | https://twitter.com/chrisdeville/status/1298060678432010240 | david foster wallace bro conversation again? i feel like by this point in the discourse i need footnotes! (just a little "insider" dfw humor for ya) | 23 |
| 2020-08-24 19:06:25+00:00 | https://twitter.com/MaraWilson/status/1297973554986639360 | david foster wallace bro conversation again? i feel like by this point in the discourse i need footnotes! (just a little "insider" dfw humor for ya) | 23 |
| 2020-10-06 21:23:56+00:00 | https://twitter.com/ben_geier/status/1313590839977947136 | the guy who publicly makes a display of how much feminist literature he reads and waxes on how important bookshelf representation is at least 50% more likely to be a sexpest than the bro who just likes to vibe about david foster wallace and hemingway. this is science. https://t.co/QsvsVxBY15 | 12 |
| 2020-10-06 16:54:42+00:00 | https://twitter.com/ben_geier/status/1313523086424186881 | the guy who publicly makes a display of how much feminist literature he reads and waxes on how important bookshelf representation is at least 50% more likely to be a sexpest than the bro who just likes to vibe about david foster wallace and hemingway. this is science. https://t.co/QsvsVxBY15 | 12 |
| 2015-08-14 11:31:24+00:00 | https://twitter.com/PublishersWkly/status/632152536636608512 | "David Foster Wallace was not a bro: Let’s not paint the writer with the same brush as his fans" | Salon http://t.co/t4FqgmoyVz | 10 |
| 2015-08-13 20:53:02+00:00 | https://twitter.com/Salon/status/631931489769390080 | David Foster Wallace was *not* a bro: Don't paint the writer with the same brush as his fans http://t.co/vZvwEien22 | 10 |
| 2015-08-13 13:31:24+00:00 | https://twitter.com/sts10/status/631820349290774528 | All men are bad but are David Foster Wallace fans a special kind of bad? http://t.co/w5KOvJBcui http://t.co/yBhOr3aPjy | 8 |
| 2015-08-13 13:52:26+00:00 | https://twitter.com/Blumsteinboy/status/631825643441901568 | You probably know a bro who says he loves David Foster Wallace: http://t.co/3KfOlw2UR6 http://t.co/xNI9tbF02p | 7 |
| 2015-08-13 13:52:02+00:00 | https://twitter.com/TheCut/status/631825543202213889 | You probably know a bro who says he loves David Foster Wallace: http://t.co/3KfOlw2UR6 http://t.co/xNI9tbF02p | 7 |
| 2015-08-13 14:02:23+00:00 | https://twitter.com/Gwen_UsBeauty/status/631828145105162240 | You probably know a bro who says he loves David Foster Wallace: http://t.co/3KfOlw2UR6 http://t.co/xNI9tbF02p | 7 |
| 2015-09-17 00:32:50+00:00 | https://twitter.com/ColinACurtis/status/644307992901517312 | Did Carly Fiorina just make a David Foster Wallace reference?\n\nIs Carly Fiorina a David Foster Wallace bro?? | 5 |
| 2015-09-17 00:33:07+00:00 | https://twitter.com/Fahrenthold/status/644308060937265152 | Did Carly Fiorina just make a David Foster Wallace reference?\n\nIs Carly Fiorina a David Foster Wallace bro?? | 5 |
| 2015-09-17 00:32:29+00:00 | https://twitter.com/MEPFuller/status/644307901830561793 | Did Carly Fiorina just make a David Foster Wallace reference?\n\nIs Carly Fiorina a David Foster Wallace bro?? | 5 |
| 2018-12-20 15:44:17+00:00 | https://twitter.com/MEPFuller/status/1075778924280471553 | Is—is Alexandria Ocasio-Cortez a David Foster Wallace bro? https://t.co/OcwGRUdWMV | 4 |
| 2017-03-22 14:13:17+00:00 | https://twitter.com/theferocity/status/844552567522820096 | "David Foster Wallace is essentially the same as skiing and cigars now.” https://t.co/GPCbgdBL3e | 4 |
| 2017-08-17 18:13:09+00:00 | https://twitter.com/thesarahkelly/status/898246334804787202 | UPDATE: I met a "Have you read David Foster Wallace?" bro at law school. It only took four days, fam. FOUR. | 1 |
| 2020-05-11 18:56:06+00:00 | https://twitter.com/MilesKlee/status/1259920233600479233 | This week for the MEL Review of Books, we had @leahrosenz talk to @adriennemiller about IN THE LAND OF MEN, a memoir of the dude snobbery she faced as the literary editor at Esquire while publishing the likes of David Foster Wallace: \nhttps://t.co/26WQYMgakO | 1 |
| 2014-12-17 01:00:01+00:00 | https://twitter.com/billroorbach/status/545020559248343040 | My blog bro David (@BDsCocktailHour) reacts to David Foster Wallace's teaching Gessner. With footnotes. #BillandDaves http://t.co/gU84ybdk2C | 1 |
| 2016-05-20 14:27:40+00:00 | https://twitter.com/MEPFuller/status/733665498148294657 | Am I a David Foster Wallace bro? Very well, I'm a David Foster Wallace bro. | 1 |
| 2012-11-19 22:54:54+00:00 | https://twitter.com/stephaniemlee/status/270661455727165442 | Ayn Rand too, bro RT @SUPSLA: of couuuuuuuuurse david foster wallace is quoted. | 0 |
| 2021-11-30 13:16:56+00:00 | https://twitter.com/TJCarpenterShow/status/1465671187497840642 | It has little to do with the gender of the author, protagonist, etc. Olga Tokarczuk is just as appealing to male readers as David Foster Wallace (who is considered 'bro lit'). It seems to be more directly related, interestingly enough, to the postmodernist divide in literature. | 0 |
| 2016-01-12 03:34:53+00:00 | https://twitter.com/Dooezer/status/686753187727044609 | "Bro stop being such a David Foster Wallace footnote" | 0 |
| 2016-02-01 18:24:47+00:00 | https://twitter.com/deep_beige/status/694224894805032964 | David Foster Wallace sucks and this is a great review of interminable jest, via @Bro_Pair https://t.co/hxGFGY6D3Z | 0 |
| 2021-07-06 10:40:49+00:00 | https://twitter.com/JeyyLowe/status/1412360883582418945 | @TomKealy2 @aveek18 @maybeavalon Imo the great twitter literature injustice is that it is david foster wallace and not him that is smeared as the dumb bro contemporary author | 0 |
| 2016-08-03 17:24:14+00:00 | https://twitter.com/rebeccamakkai/status/760889024403873792 | New theory: Bernie Bro holdouts are exactly the same people as David Foster Wallace fanatics. Yes? | 0 |
| 2018-05-13 02:15:17+00:00 | https://twitter.com/nandelabra/status/995487617549512704 | I got kicked out of KGB Bar in the LES for arguing with a lit bro that David Foster Wallace is a better writer than Thomas Pynchon. https://t.co/iQLxduLtEN | 0 |
| 2019-03-22 14:51:51+00:00 | https://twitter.com/BMcGfresh/status/1109105414849921029 | "The Great White Male is rap's Grand Inquisitor, its idiot questioner, its Alien Other no less than Reds were for McCarthy." -- David Foster Wallace, on his forays into Dorchester & Roxbury's music scenes, 1989\n\n"I know bro, but still-" -- Brendan McGuirk, reflecting on it, 2019 https://t.co/lYJV5bU7yb | 0 |
| 2020-08-20 15:18:35+00:00 | https://twitter.com/ben_a_goldfarb/status/1296466668898717696 | (Gonna out myself as an insufferable millennial bro and say David Foster Wallace—his maximalism expands my sense of what's possible on the page, as does his notorious blend of academic and colloquial prose. I swear the copy of INFINITE JEST on my shelf is not a display piece.) | 0 |
| 2021-06-26 17:04:10+00:00 | https://twitter.com/adamdavidson/status/1408833479304003589 | @page88 @IngrahamAngle I heard a tech bro quote a line about cruise ship wait staff from David Foster Wallace's A Supposedly Fun Thing and said it showed how DFW really believed in great customer service. | 0 |
| 2011-12-12 20:48:07+00:00 | https://twitter.com/DrownedinSound/status/146330510422048768 | @MelodicRecords chillax brother, we all gud. Put another blunt on the barbie 'n' go wid th' flo bro. Dude man... http://t.co/q0RUmv12 | 0 |
Top Hashtags#
To analyze hashtags in a tweet dataset, we can use the plugin twarc2 hashtags, which requires a separate installation.
!pip install twarc-hashtags
Then we can create a CSV digest of the top hashtags from our JSONL data with twarc2 hashtags. (To get more hashtag data, we are using a JSONL file that contains a full archive search of “David Foster Wallace” rather than “David Foster Wallace bro”).
!twarc2 hashtags twitter-data/dfw.jsonl twitter-data/dfw_hashtags.csv
100%|██████████████| Processed 56.9M/56.9M of input file [00:01<00:00, 35.0MB/s]
pd.read_csv('twitter-data/dfw_hashtags.csv')
| hashtag | tweets | |
|---|---|---|
| 0 | dfw | 202 |
| 1 | writing | 154 |
| 2 | davidfosterwallace | 122 |
| 3 | amwriting | 114 |
| 4 | longreads | 103 |
| ... | ... | ... |
| 1428 | 24hourbookclub | 1 |
| 1429 | 21février | 1 |
| 1430 | 1980s | 1 |
| 1431 | 12sep2008 | 1 |
| 1432 | 100novelas | 1 |
1433 rows × 2 columns
We can also use the flag --group to group the hashtags by their frequency per time period and the flag --limit to limit the hashtags to only the top n number of hashtags per grouping.
!twarc2 hashtags --group year --limit 10 twitter-data/dfw.jsonl twitter-data/dfw_hashtags_year.csv
100%|██████████████| Processed 56.9M/56.9M of input file [00:01<00:00, 34.9MB/s]
hashtags_df = pd.read_csv('twitter-data/dfw_hashtags_year.csv')
hashtags_df
| hashtag | time | tweets | |
|---|---|---|---|
| 0 | quote | 2021 | 7 |
| 1 | writing | 2021 | 6 |
| 2 | amwriting | 2021 | 5 |
| 3 | writingcommunity | 2021 | 2 |
| 4 | writetip | 2021 | 2 |
| ... | ... | ... | ... |
| 150 | dfw | 2009 | 2 |
| 151 | archive | 2009 | 2 |
| 152 | wallace | 2009 | 1 |
| 153 | swf | 2009 | 1 |
| 154 | reading | 2009 | 1 |
155 rows × 3 columns
To plot the frequency of hashtags over time, we can set the DataFrame index to the “time” column.
hashtags_df = hashtags_df.set_index('time')
Then we can filter for a specific hashtag and plot its frequency.
hashtags_df[hashtags_df['hashtag'] == 'writing'].plot(y='tweets', label='#writing', title='DFW Hashtags');
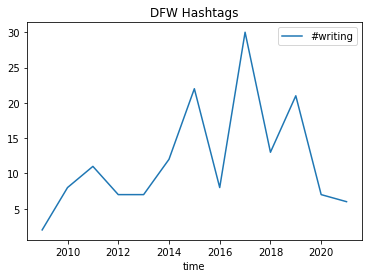
We can also plot multiple hashtags on the same plot by assigning the first plot to the variable main_axis and then directing the next plots to be plotted on the same axis ax=main_axis.
main_axis = hashtags_df[hashtags_df['hashtag'] == 'writing'].plot(y='tweets', label='#writing', title='DFW Hashtags')
hashtags_df[hashtags_df['hashtag'] == 'dfw'].plot(ax=main_axis, y='tweets', label='#dfw')
hashtags_df[hashtags_df['hashtag'] == 'infinitejest'].plot(ax=main_axis, y='tweets', label='#infinitejest');
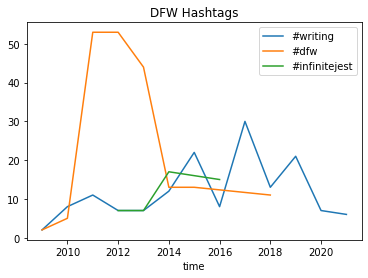
Sentiment Analysis#
See an example of running the English-language sentiment analysis tool VADER on Donald Trump’s tweets.
Topic Modeling Tweets#
See an example of using topic modeling on Donald Trump’s tweets.